#1:365建站器数据采集教程:如何填写采集网址与采集规则
本帖最后由 365站群教程 于 2019-9-17 21:39 编辑1、本教程以中彩网(http://www.zhcw.com/)的文章采集来进行演示:
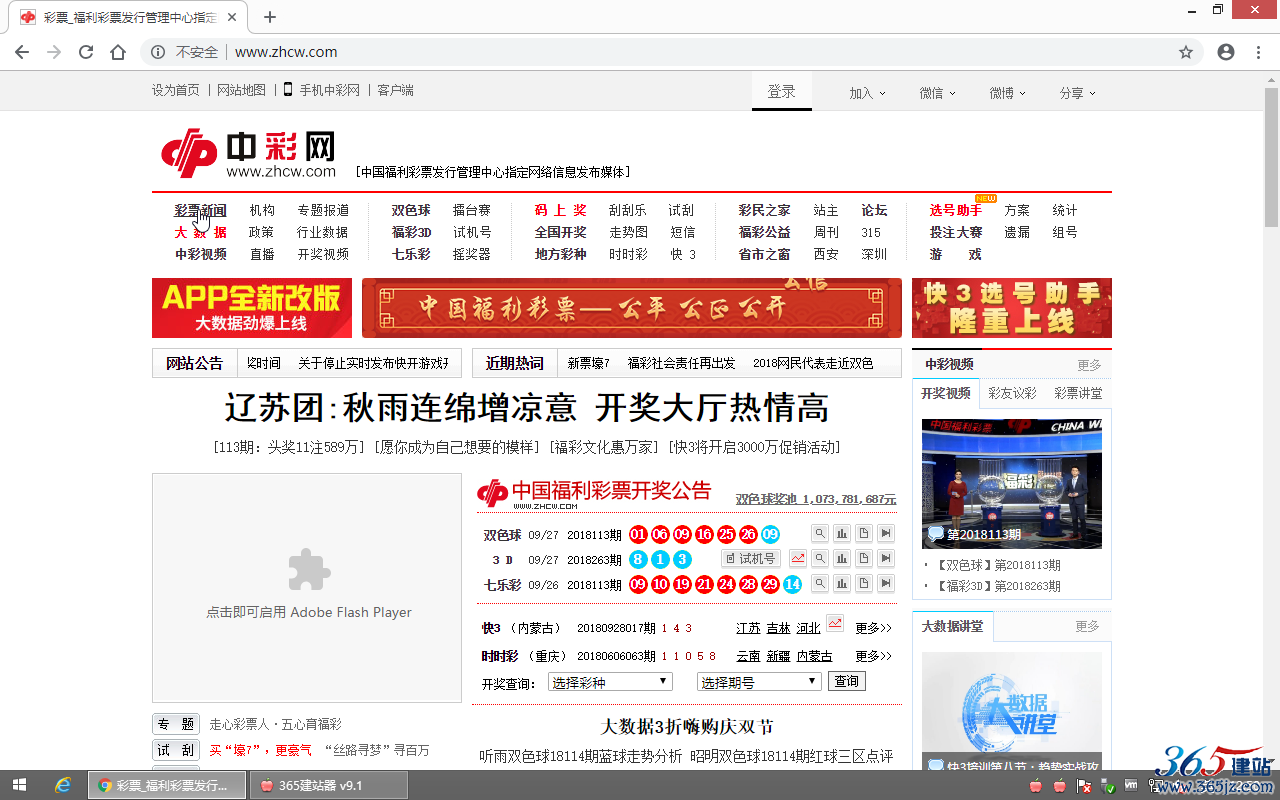
| 栏目 | 栏目网址 | 内容板块 | 内容板块网址 |
| 彩票新闻 | http://www.zhcw.com/xinwen/ | 双色球新闻 | http://www.zhcw.com/xinwen/caizhongxinwen-ssq/ |
| 彩票新闻 | http://www.zhcw.com/xinwen/ | 双色球中奖报道 | http://www.zhcw.com/xinwen/caimingushi/ssq/ |
| …… | …… | …… | …… |
2、点击软件的“数据采集”,“新建”一个采集项目:
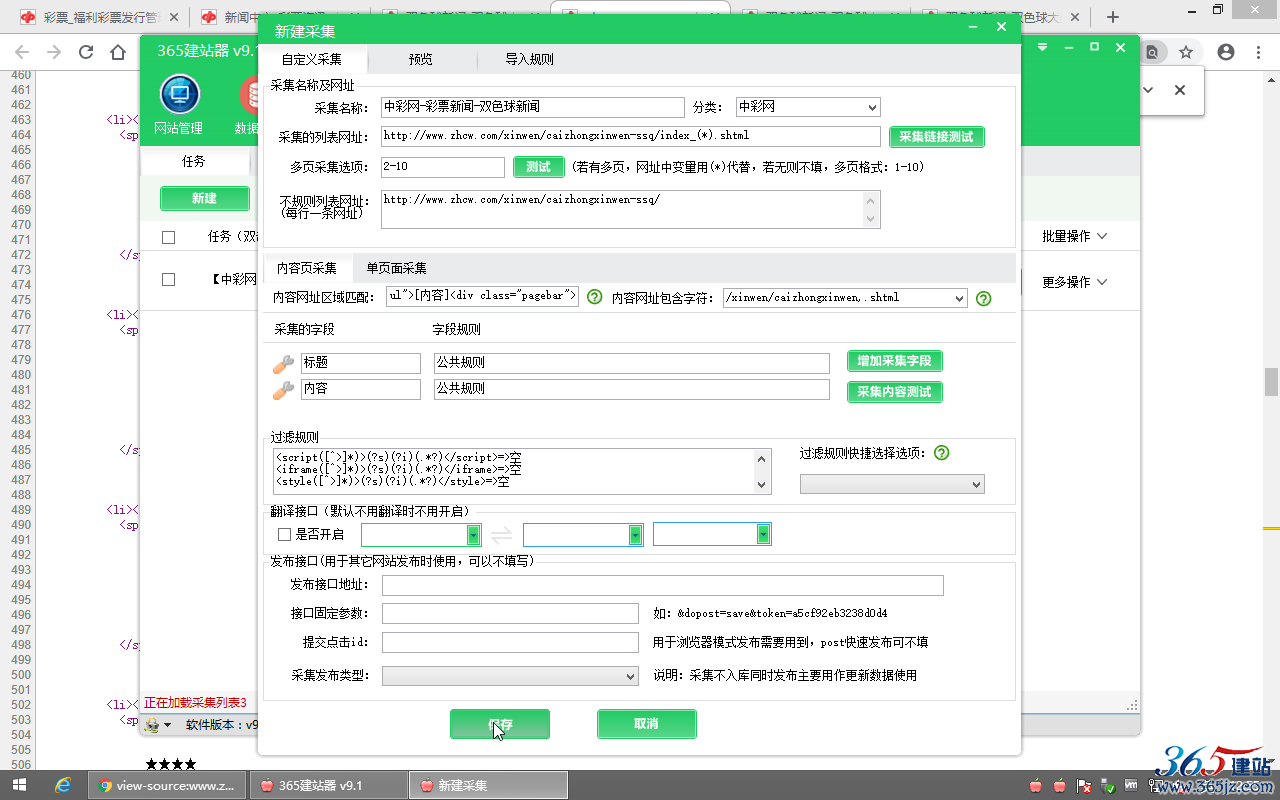
填写采集名称和分类,
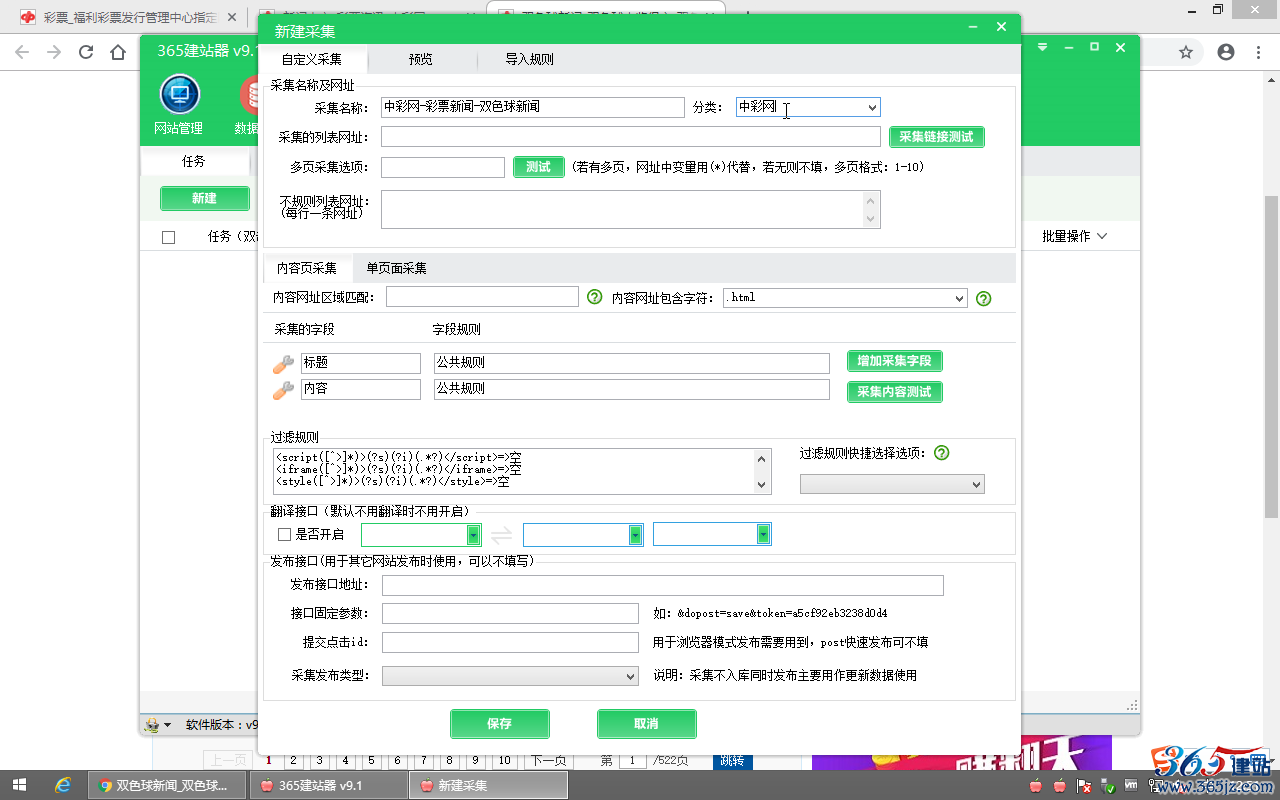
“采集名称”(自定义填写,方便自己识别)
填写:中彩网-彩票新闻-双色球新闻
“分类”(自定义填写,方便分组)
填写:中彩网
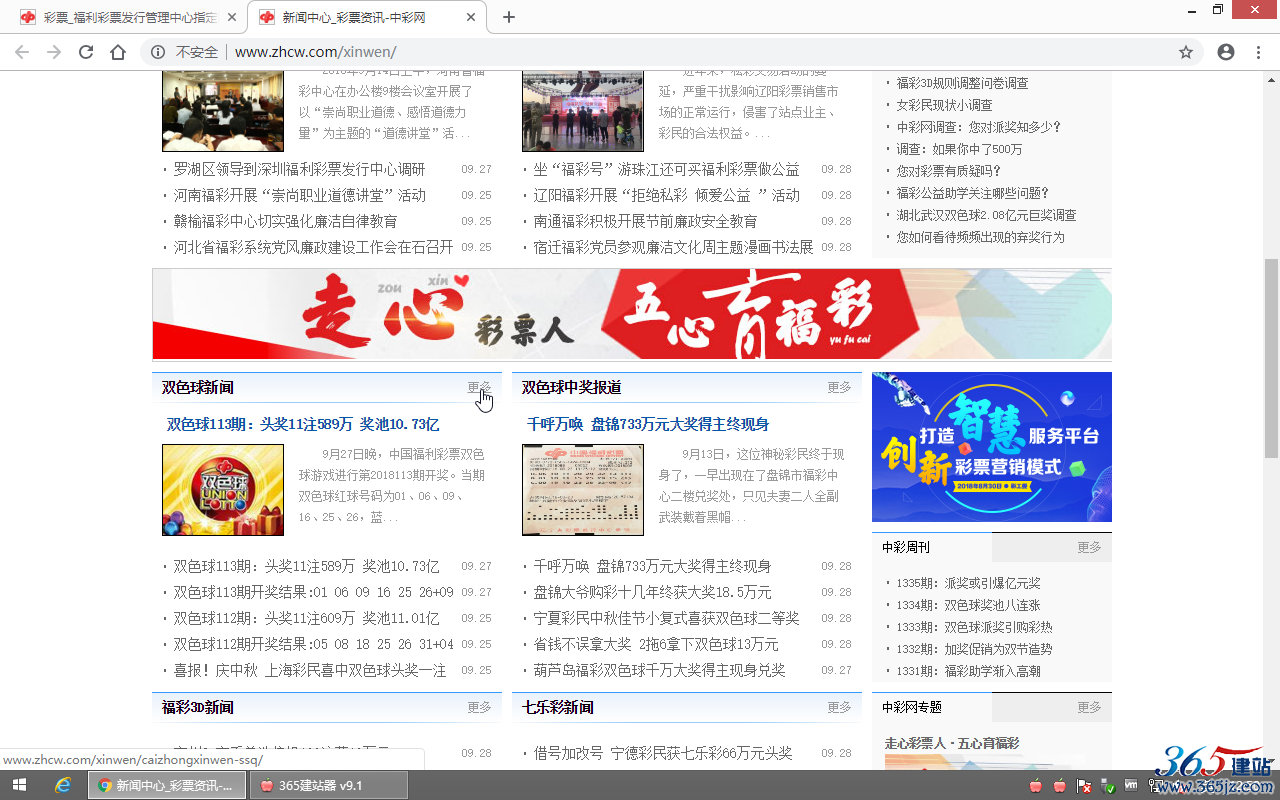
3、查看内容板块“双色球新闻”列表页的页码特点:
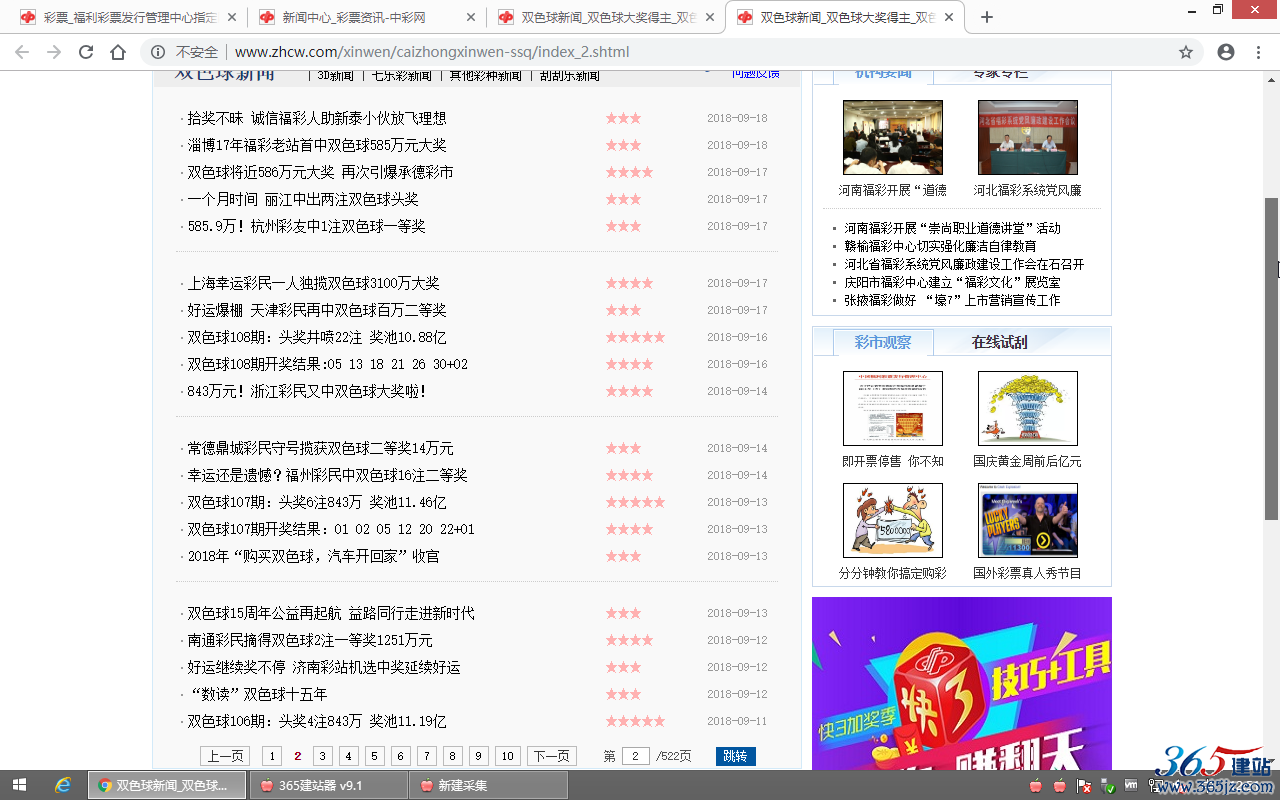
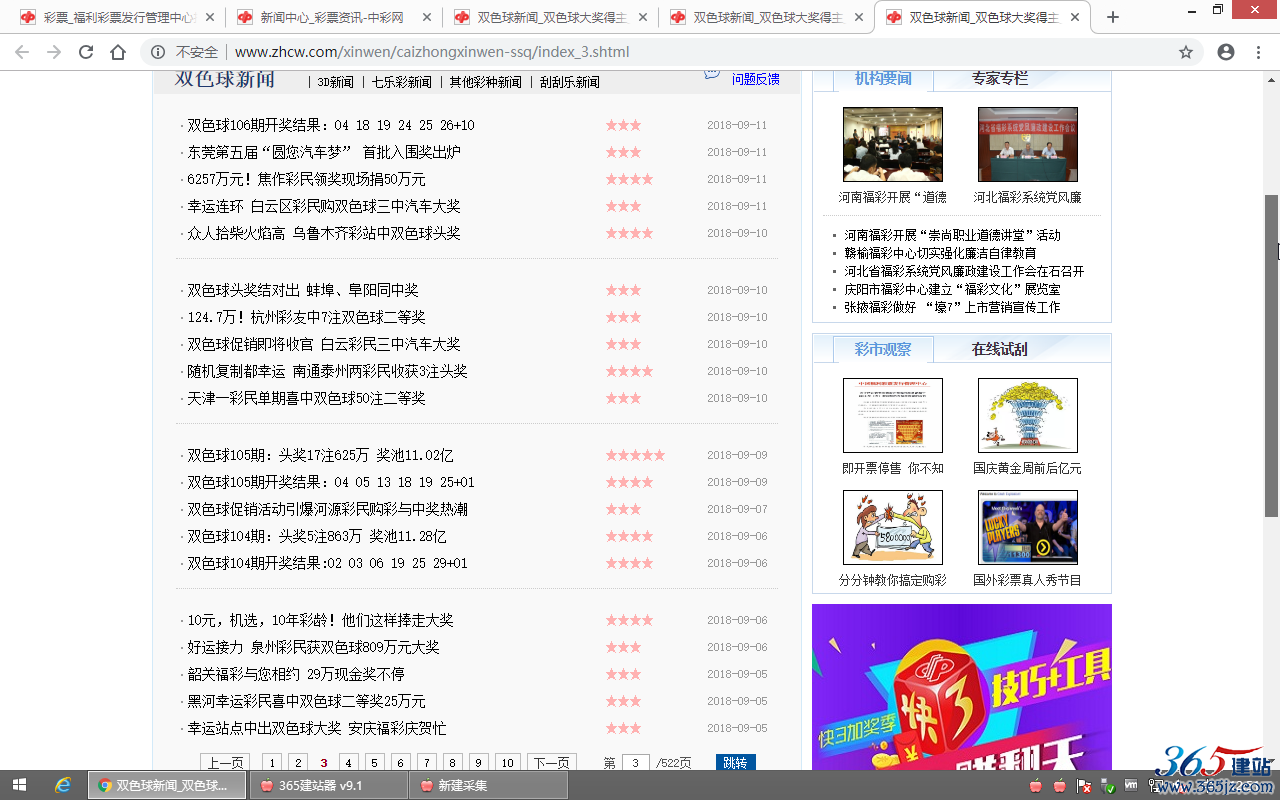
| 首页(第1页): | http://www.zhcw.com/xinwen/caizhongxinwen-ssq/ |
| 第2页: | http://www.zhcw.com/xinwen/caizhongxinwen-ssq/index_2.shtml |
| 第3页: | http://www.zhcw.com/xinwen/caizhongxinwen-ssq/index_3.shtml |
| 第4页: | http://www.zhcw.com/xinwen/caizhongxinwen-ssq/index_4.shtml |
| …… | …… |
4、分析采集网址并填写相关值:
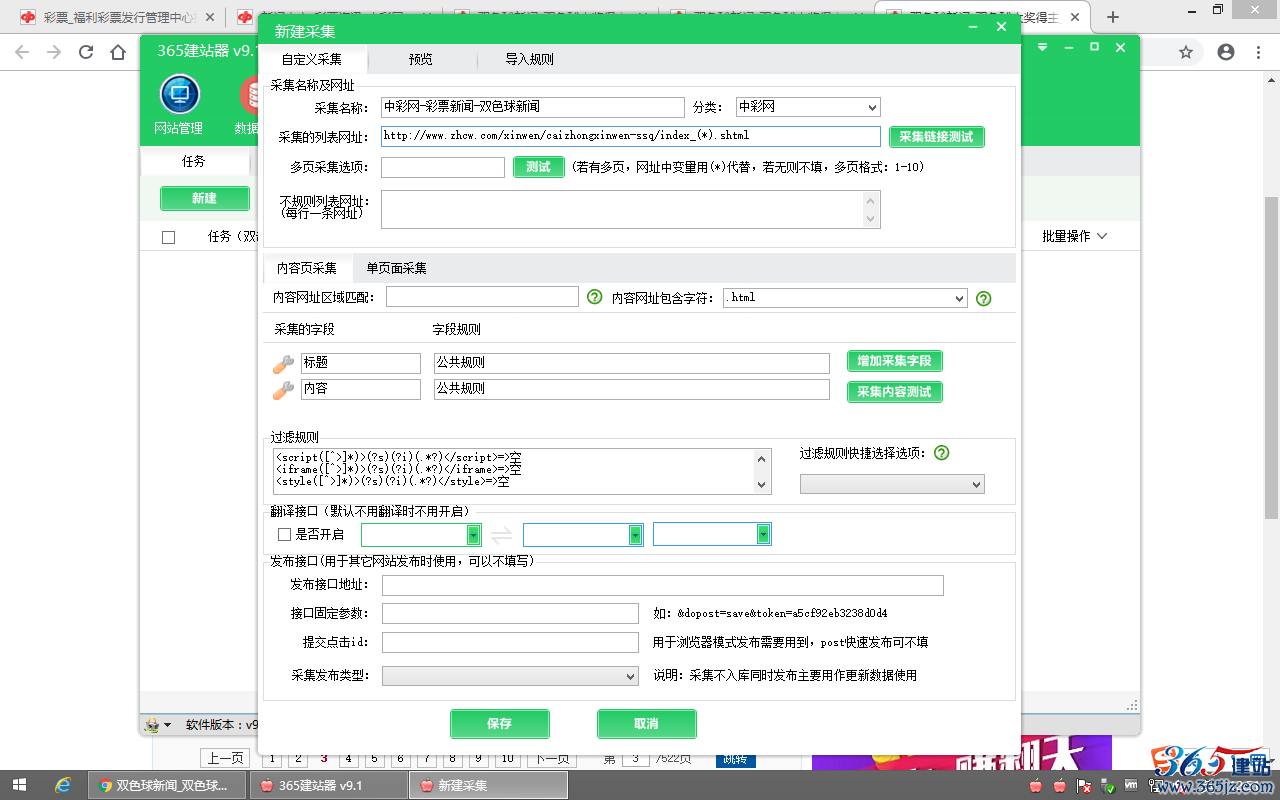
从第2页开始,页码数字是有规律的递增,将链接中的页码数字用(*)代替,均为英文状态下的字符,
“采集的列表网址”
填写:http://www.zhcw.com/xinwen/caizhongxinwen-ssq/index_(*).shtml
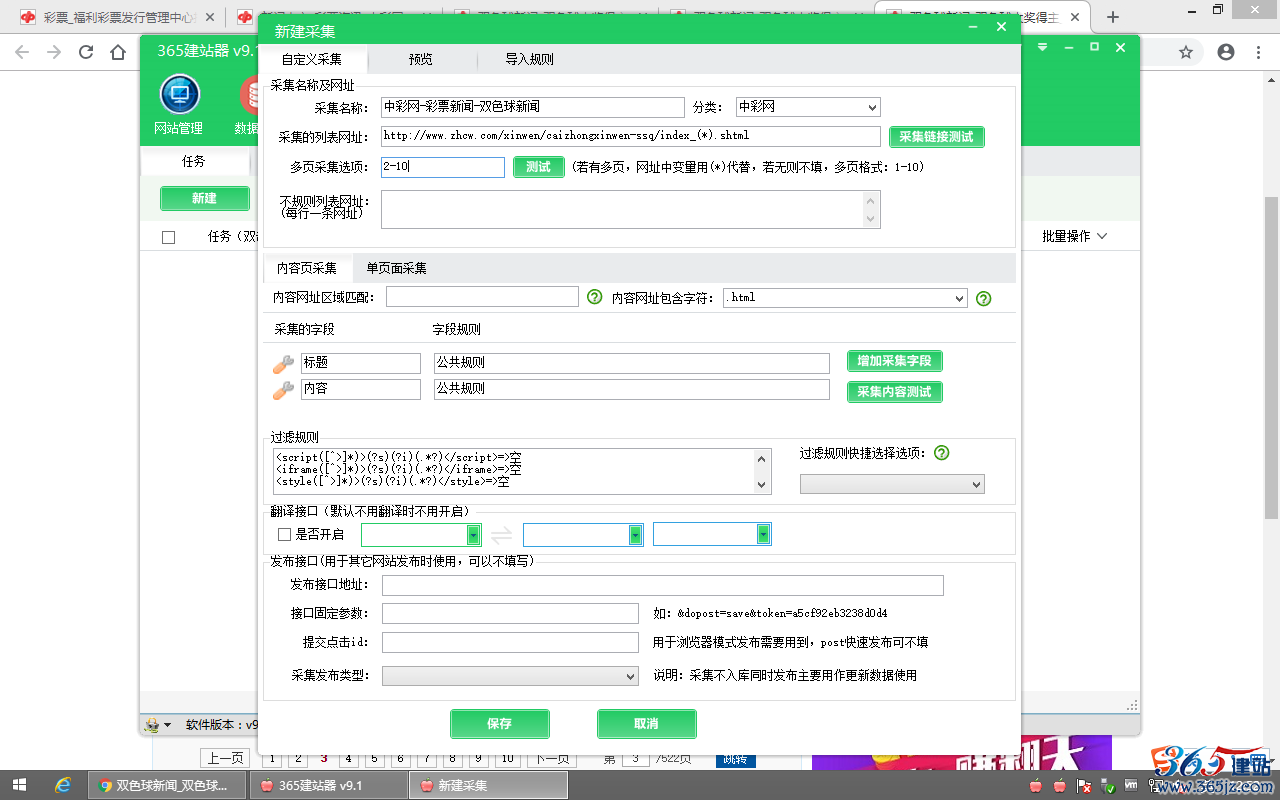
“多页采集选项”(只要页码数值有效,能正常访问即可)
填写页码区间:2-10
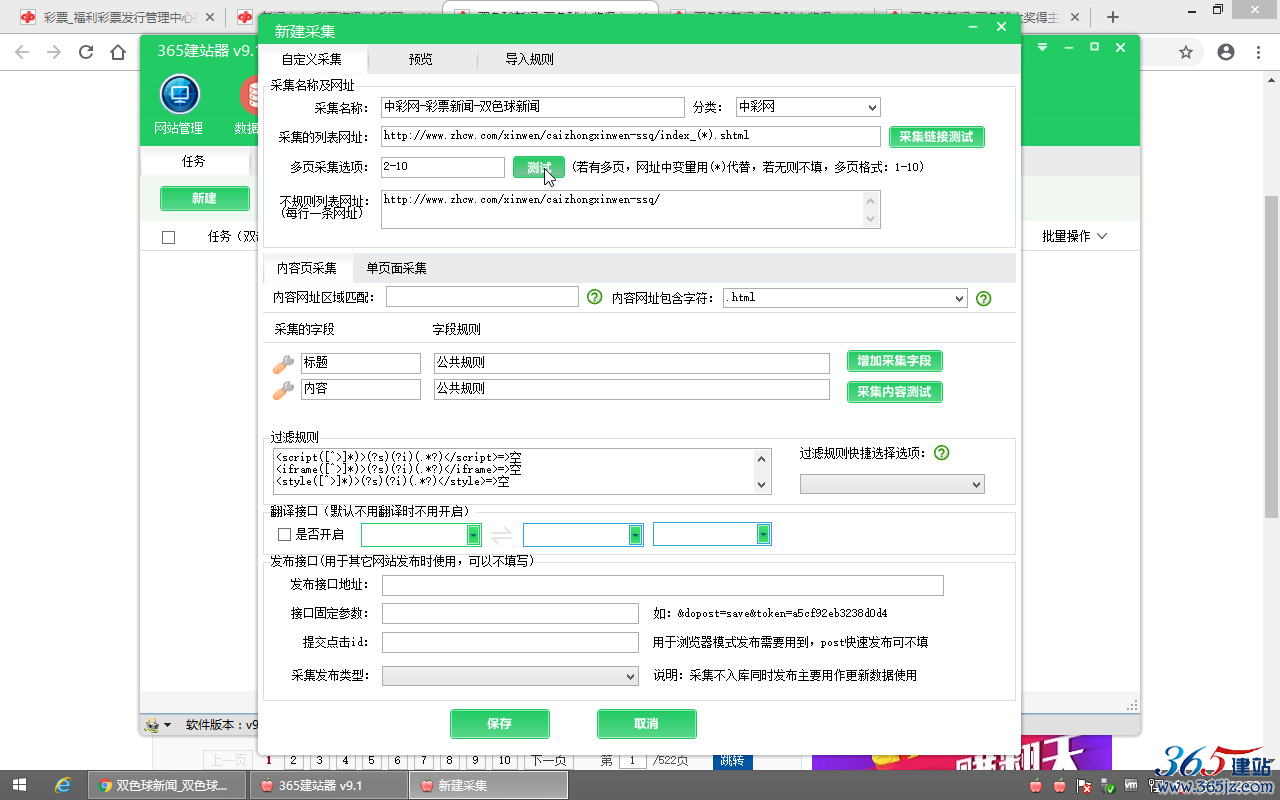
“不规则列表网址”(一般用于填写无页码数字的第1页,此项为选填,可忽略)
填写:http://www.zhcw.com/xinwen/caizhongxinwen-ssq/
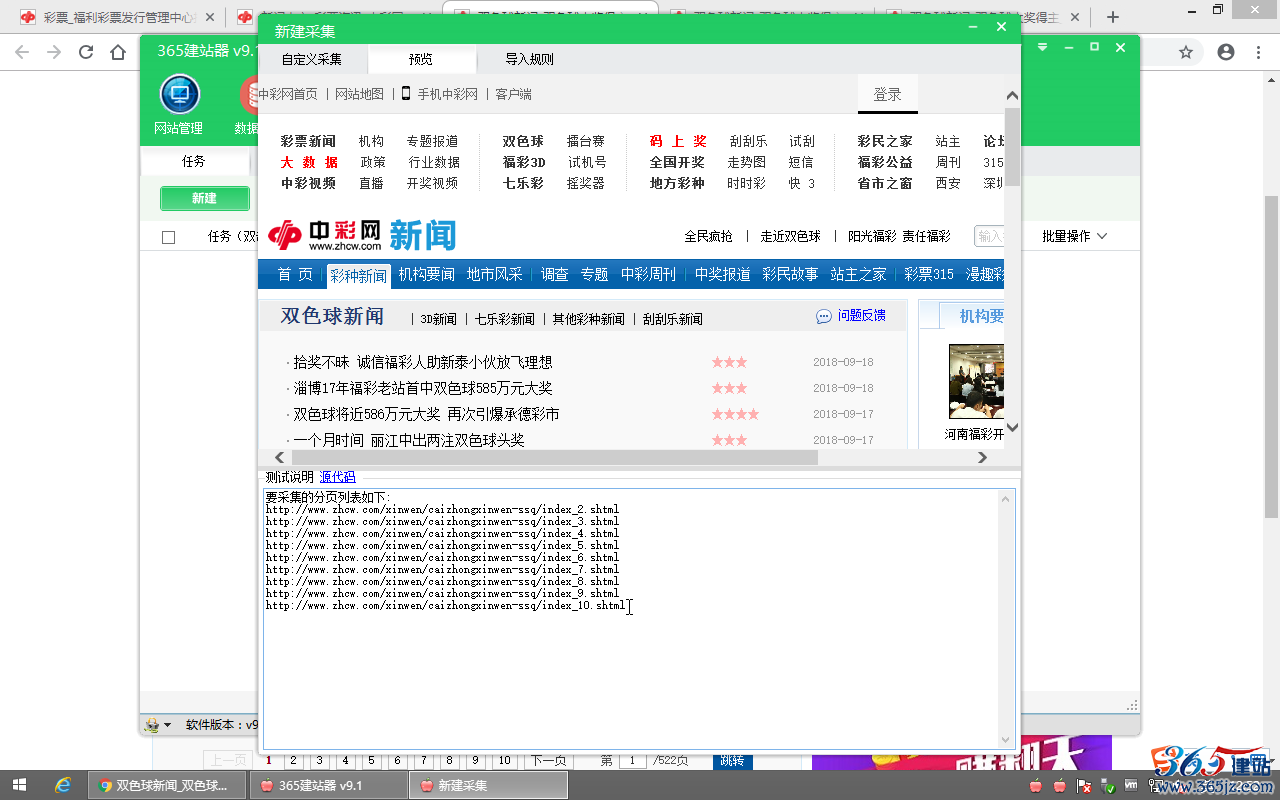
点击“多页采集选项”,即页码区间后面的“测试”,查看到多页链接预览,确认无误。
5、确定“内容网址区域匹配”和“内容网址包含字符”:
利用Chrome浏览器右键“检查”或者查看列表页源代码,确定“内容网址区域匹配”,
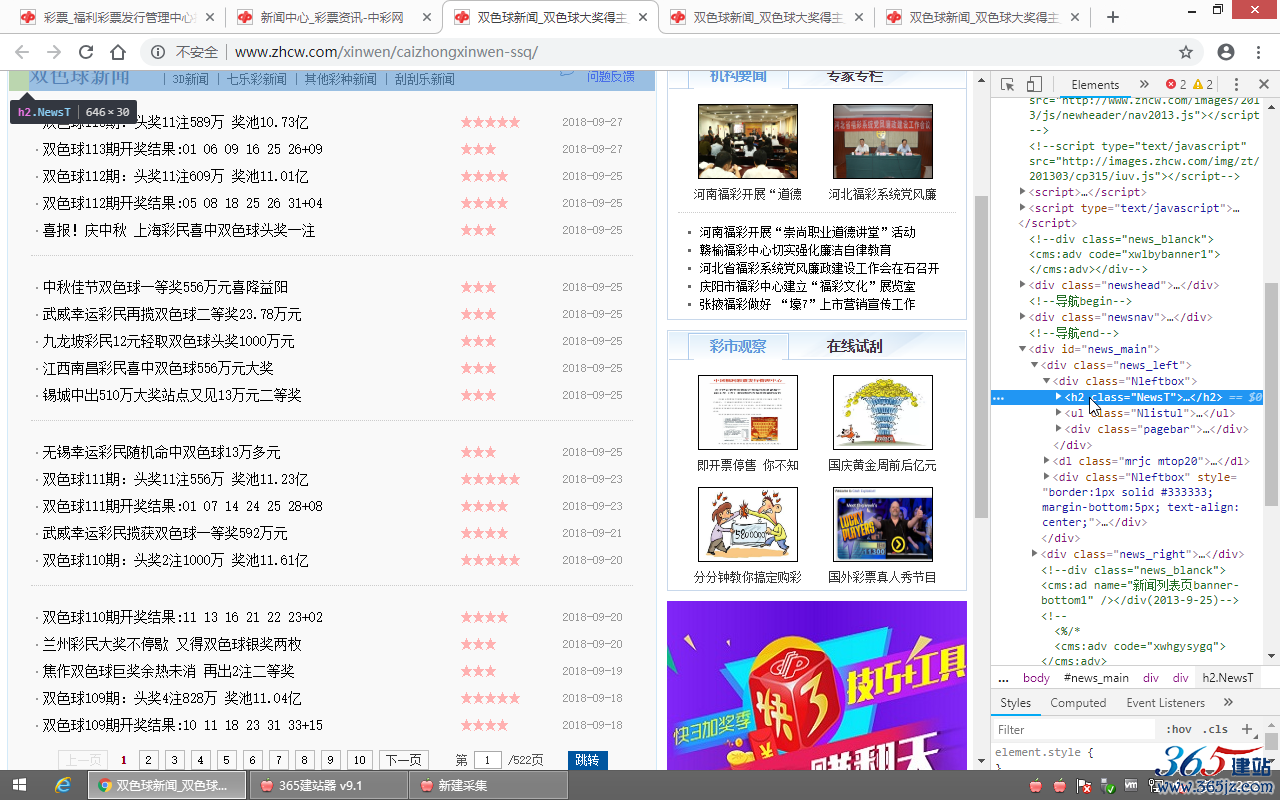
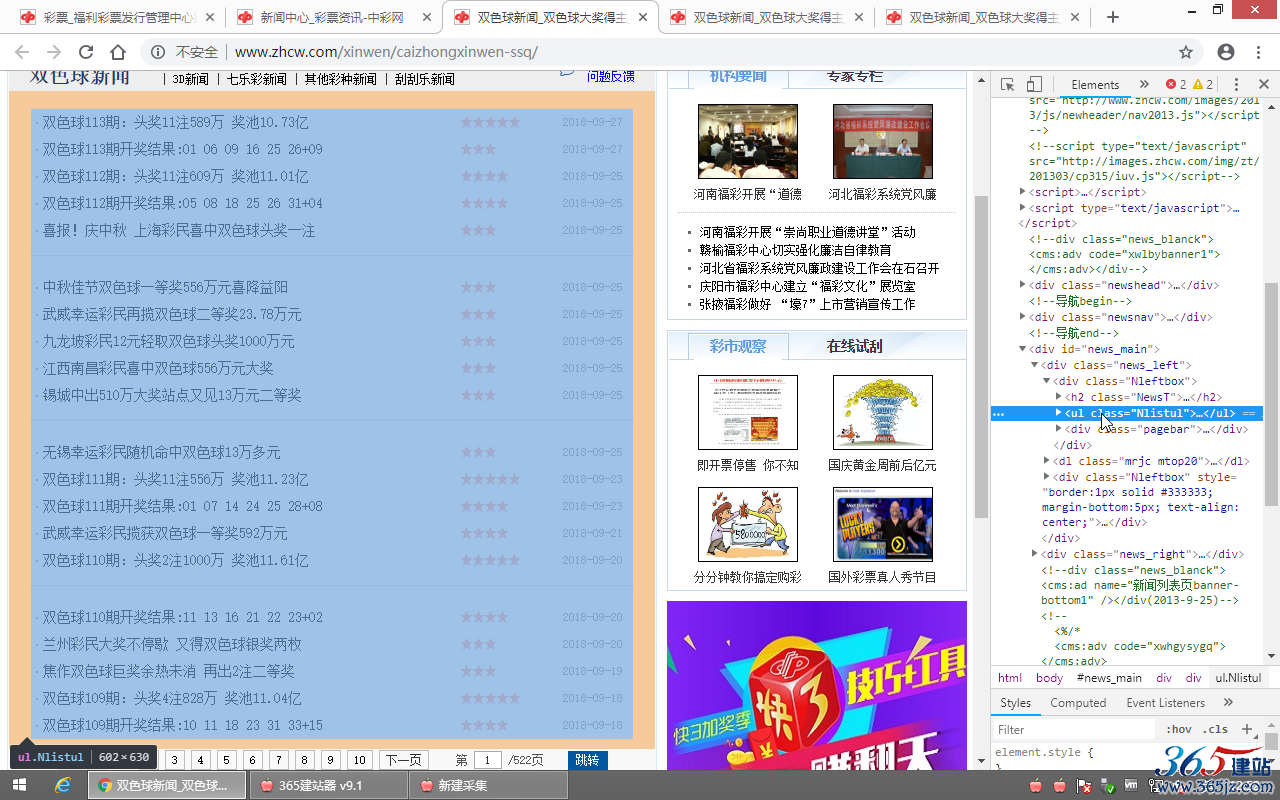
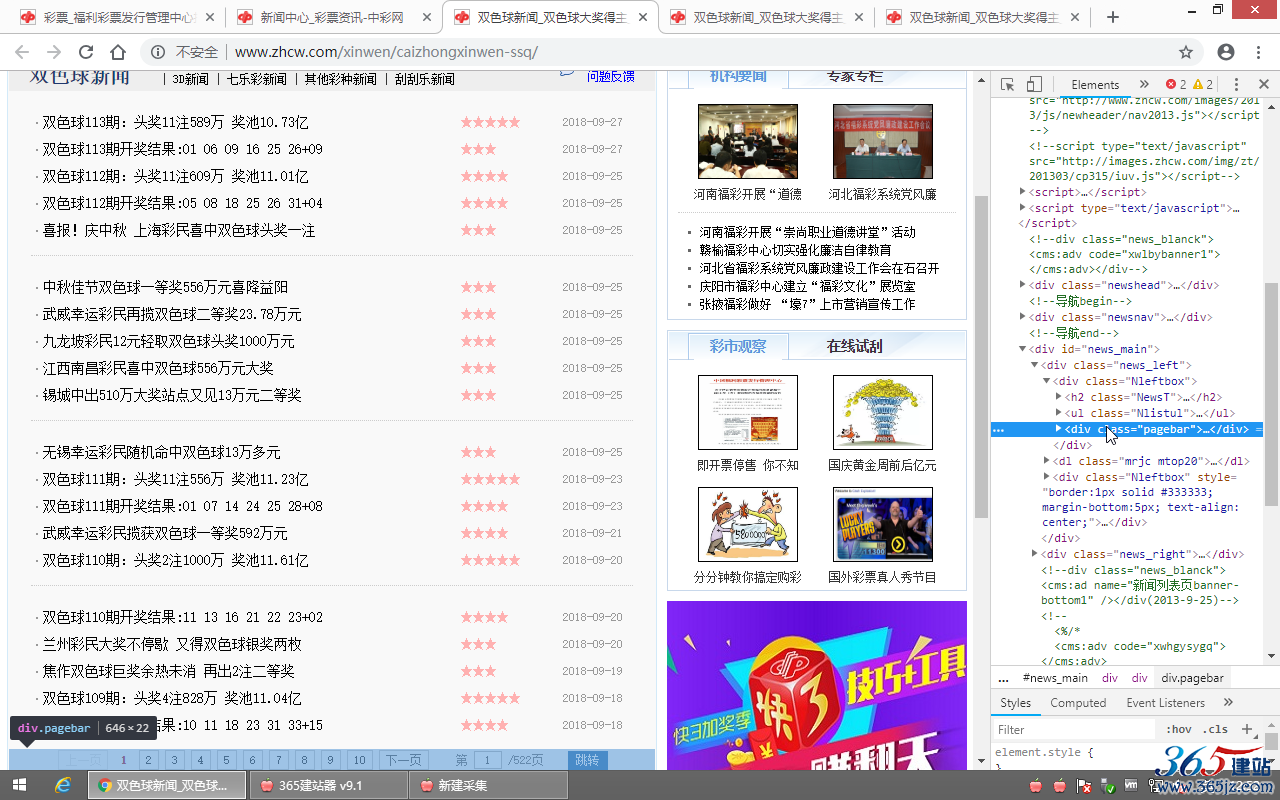
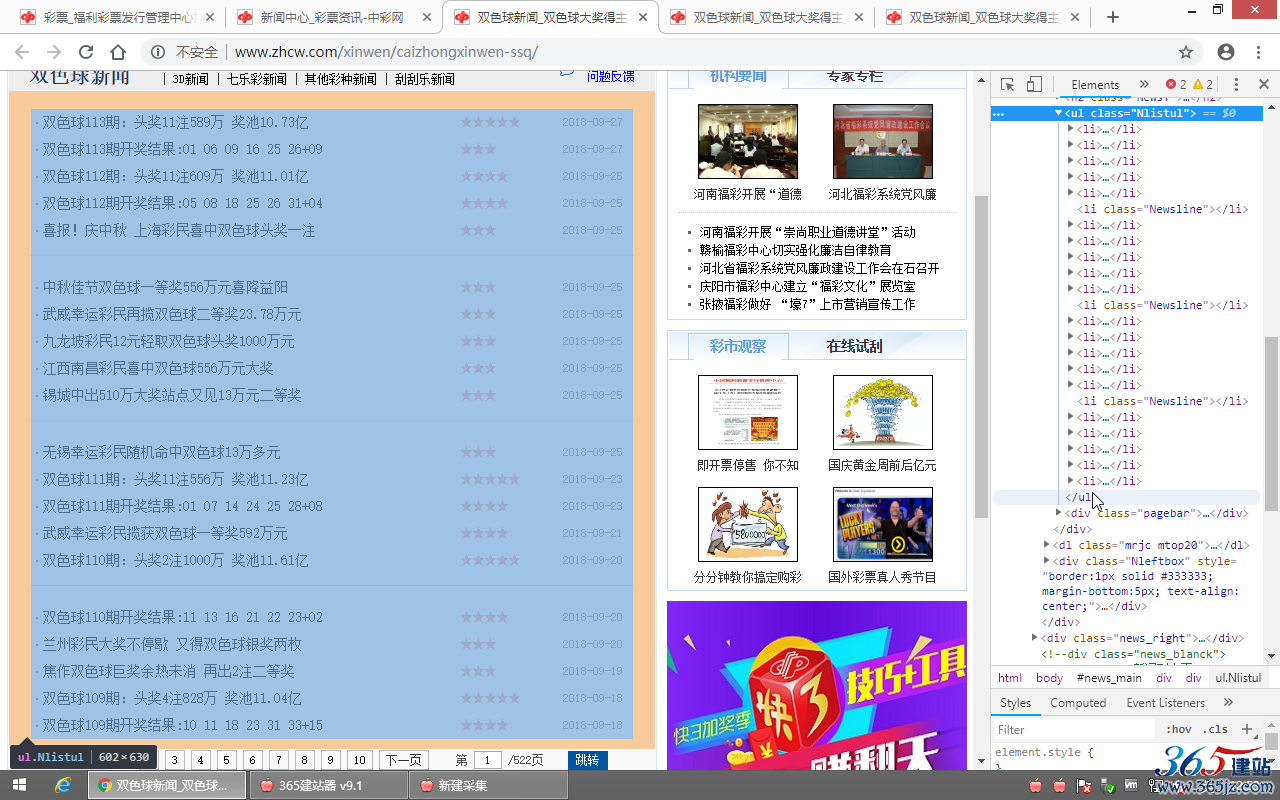
确定内容网址区域为:
<ul class="Nlistul">和<div class="pagebar">之间
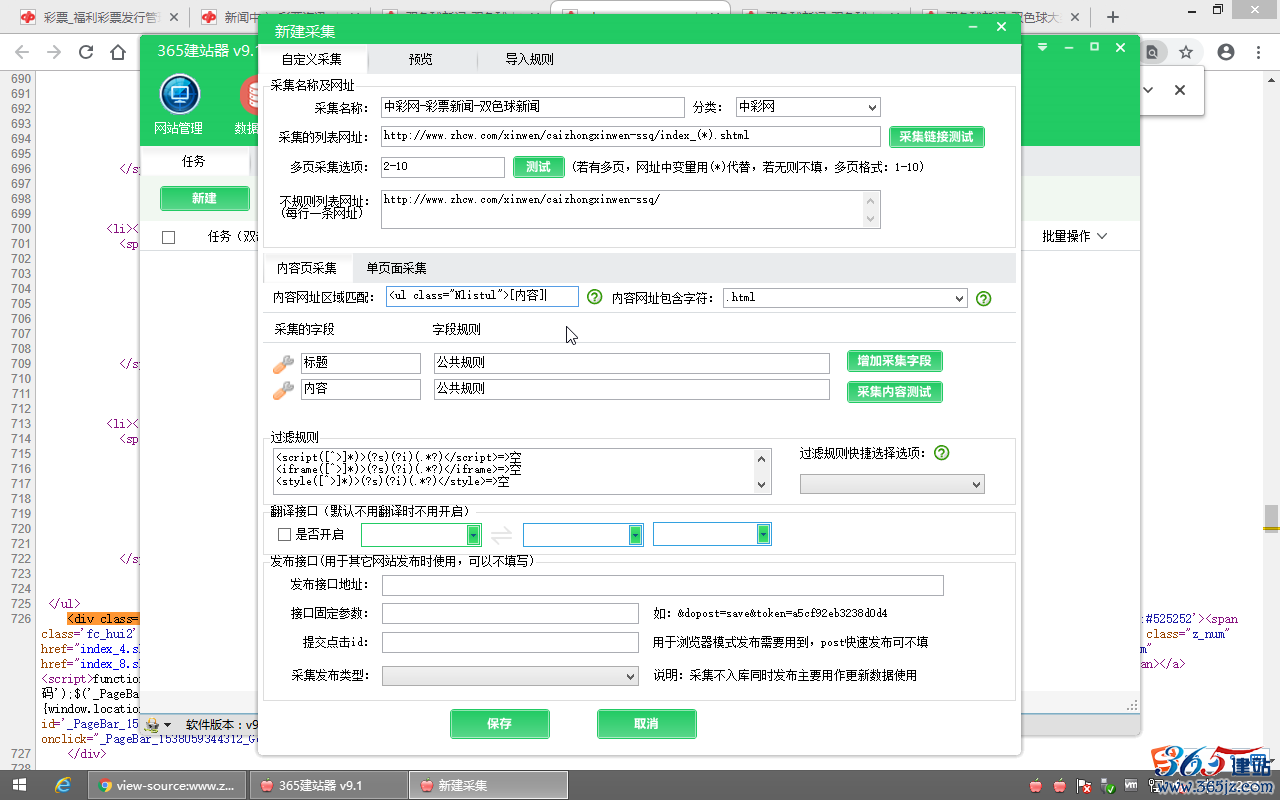
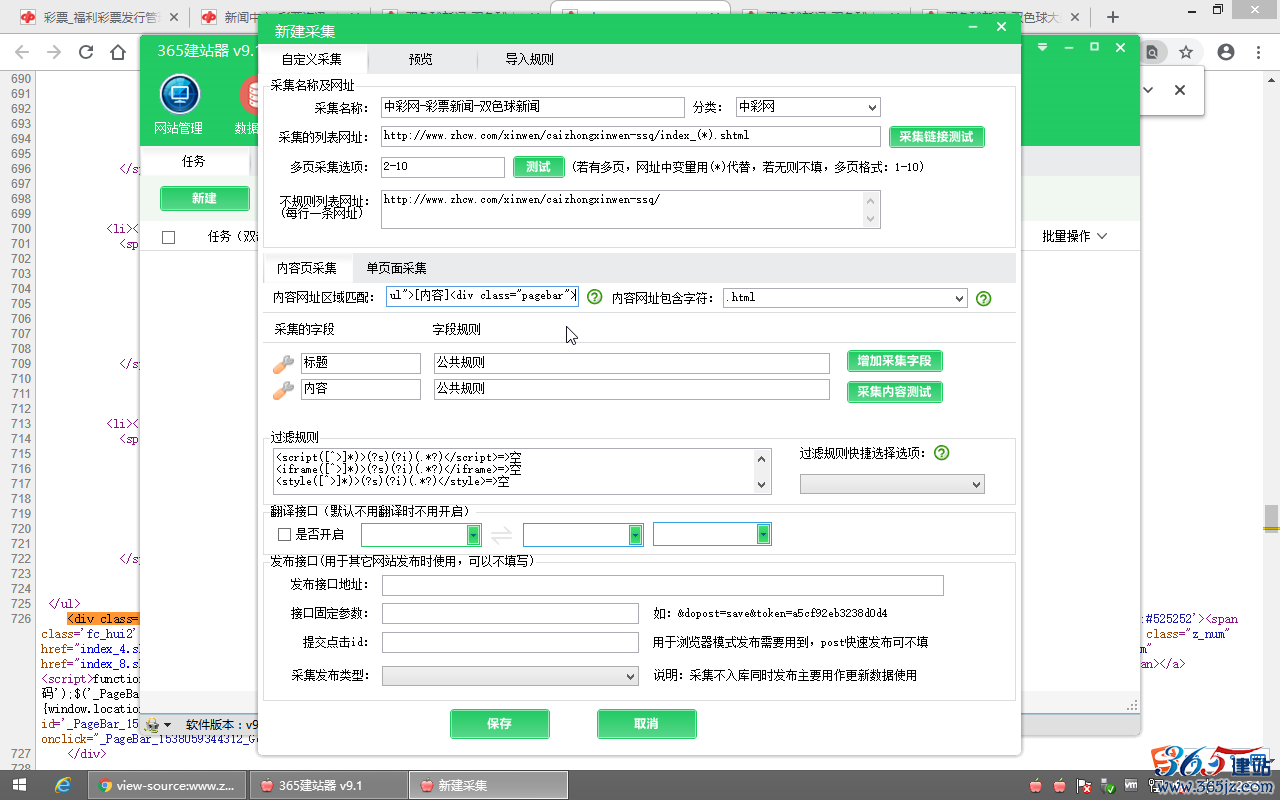
“内容网址区域匹配”(格式:开头字符串[内容]结尾字符串)
填写:<ul class="Nlistul">[内容]<div class="pagebar">
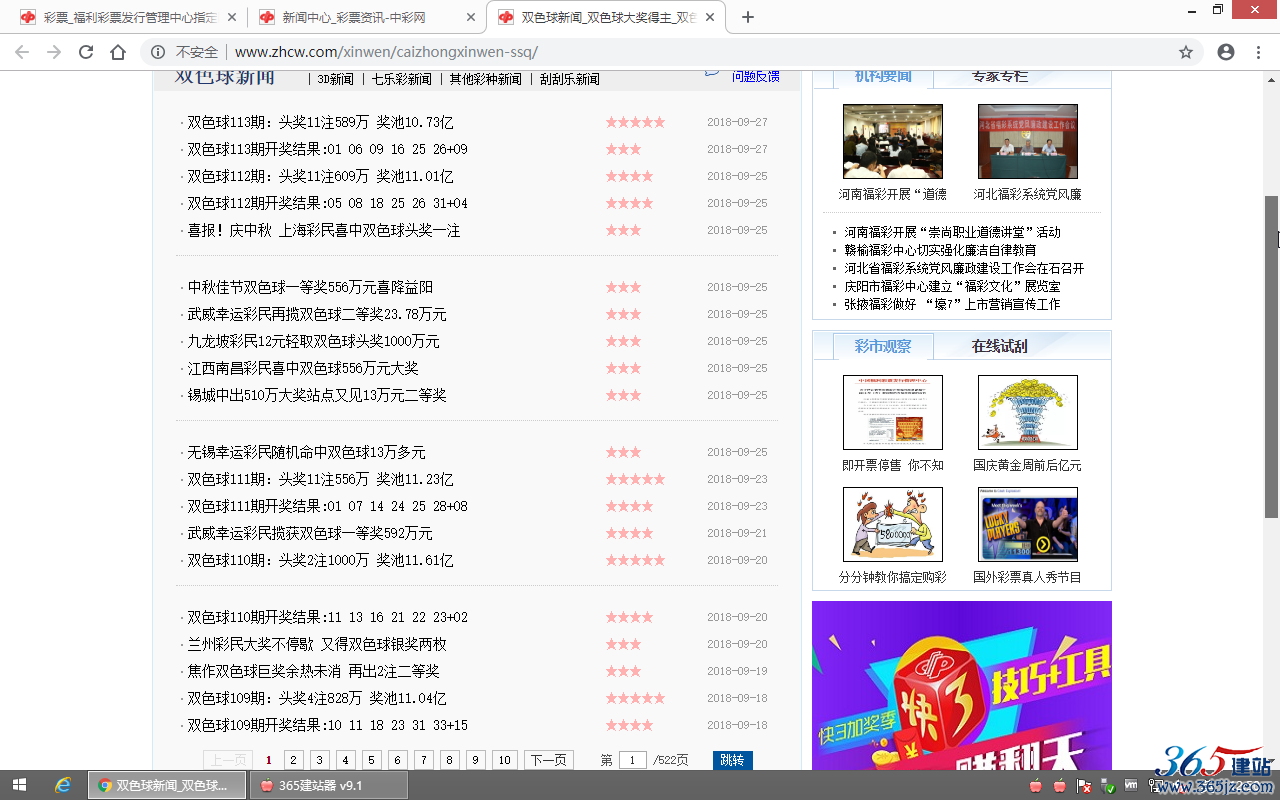
多查看几个内容网址,确定“内容网址包含字符”:
| 内容标题 | 内容网址 |
| 双色球113期:头奖11注589万 奖池10.73亿 | http://www.zhcw.com/xinwen/caizhongxinwen-ssq/19580028.shtml |
| 双色球113期开奖结果:01 06 09 16 25 26+09 | http://www.zhcw.com/xinwen/caizhongxinwen-ssq/19579015.shtml |
| 双色球112期:头奖11注609万 奖池11.01亿 | http://www.zhcw.com/xinwen/caizhongxinwen-ssq/19542774.shtml |
| …… | …… |
提取出内容网址的相同特性值:
都包含:www.zhcw.com/xinwen/caizhongxinwen-ssq/ 和 .shtml
或者短一点的:
都包含:/xinwen/caizhongxinwen 和 .shtml
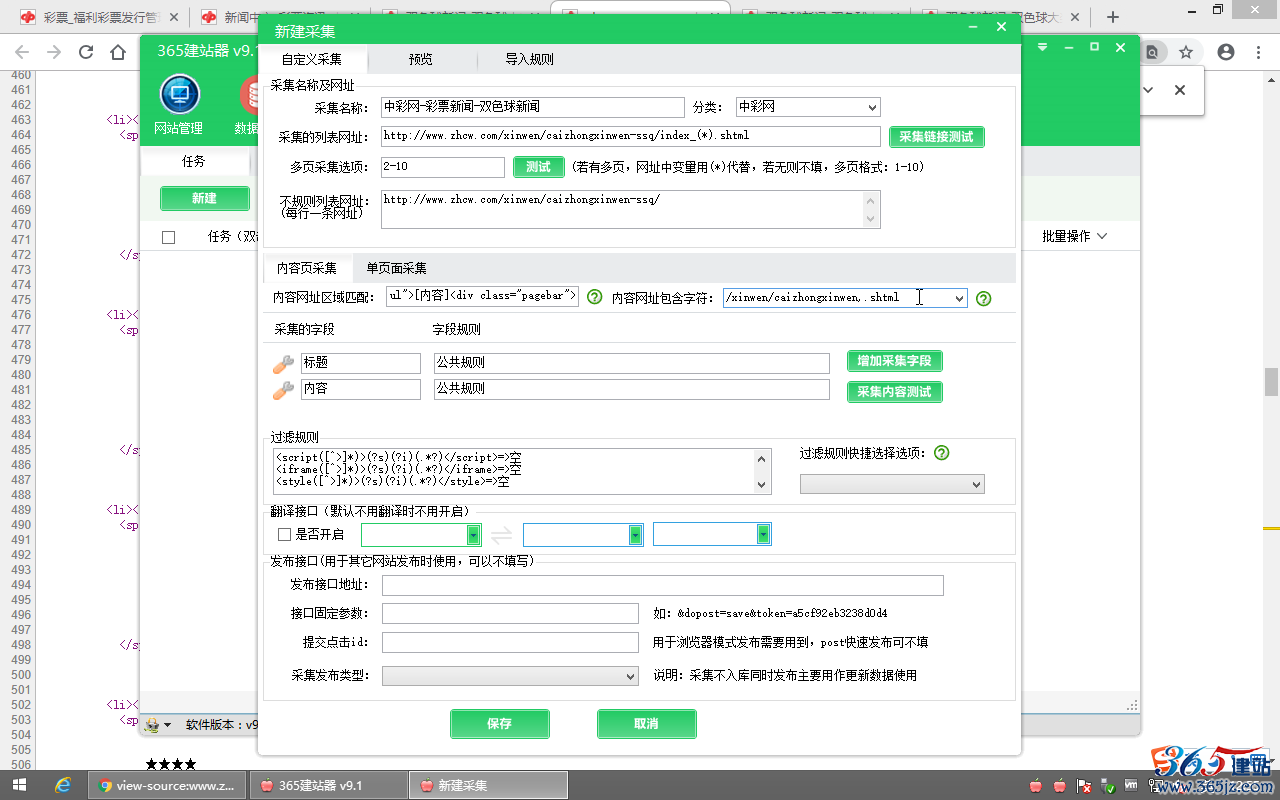
“内容网址包含字符”多项用英文逗号,分隔开,
填写:/xinwen/caizhongxinwen,.shtml
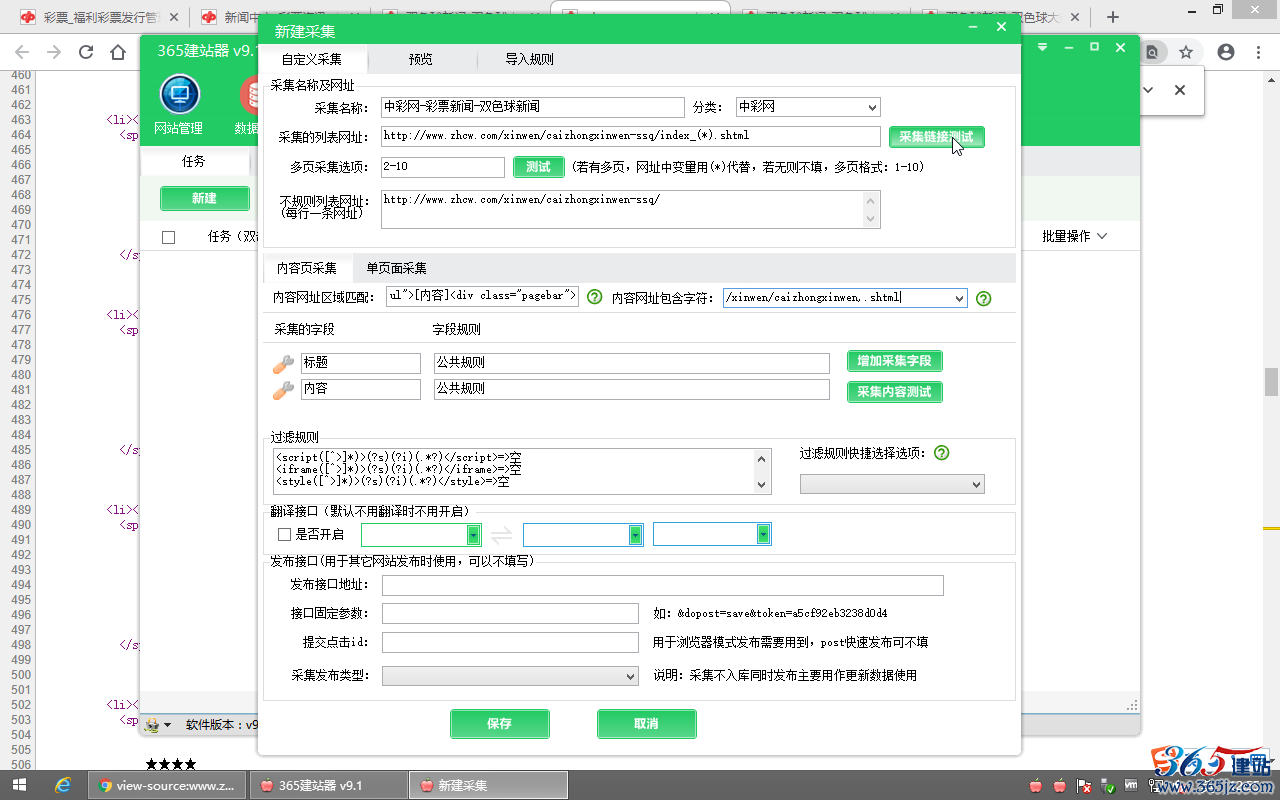
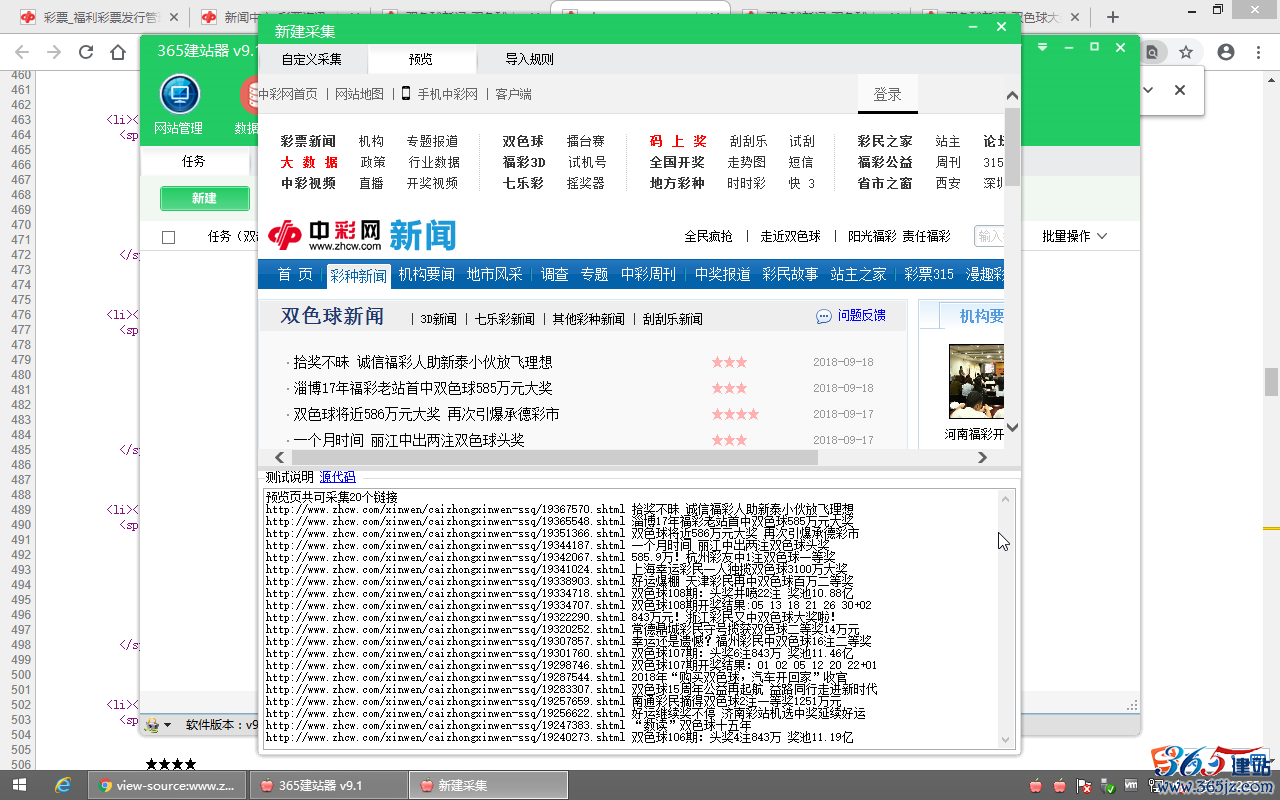
然后点击“采集的列表网址”后面的“采集链接测试”,查看到内容网址列表的预览,确认无误:
6、利用内置的公共规则,采集内容测试:
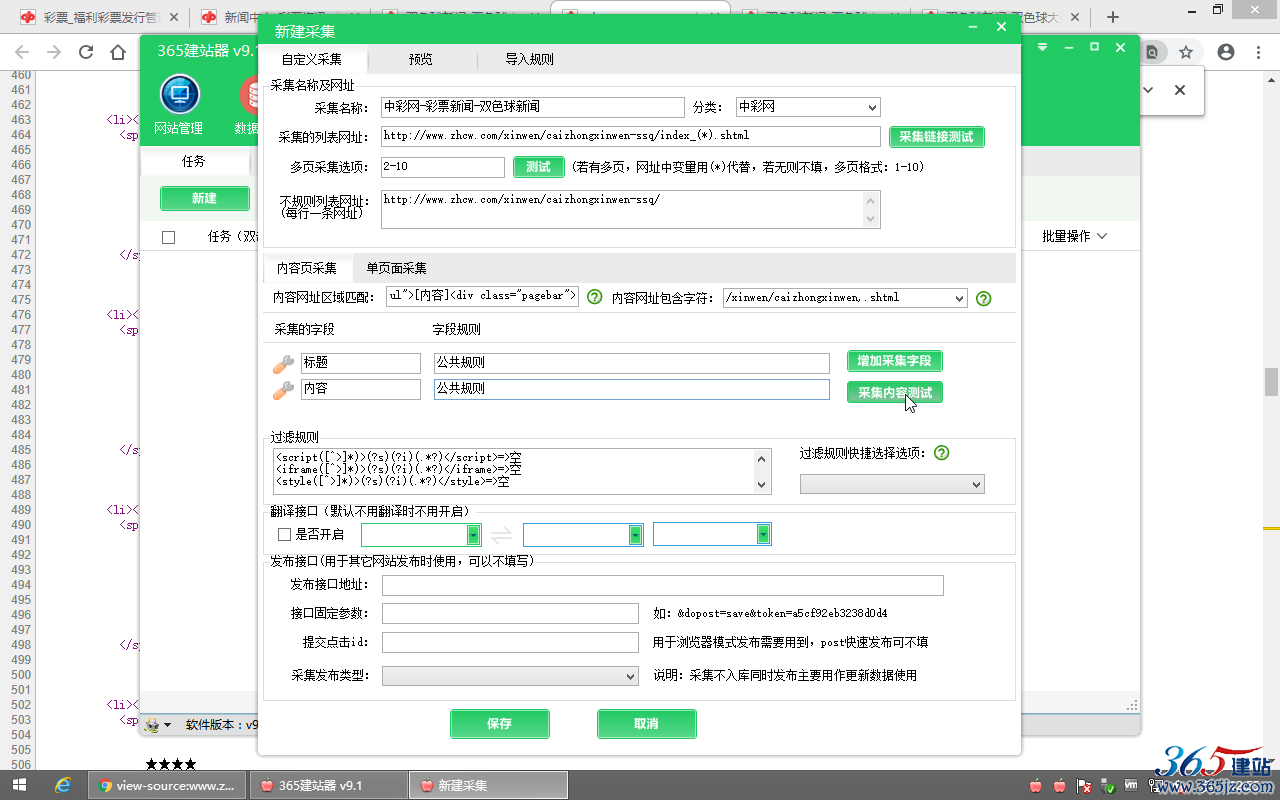
软件集成有内置的“公共规则”,可以采集到大部分网站的标题与内容,可以先用公共规则进行采集内容测试,
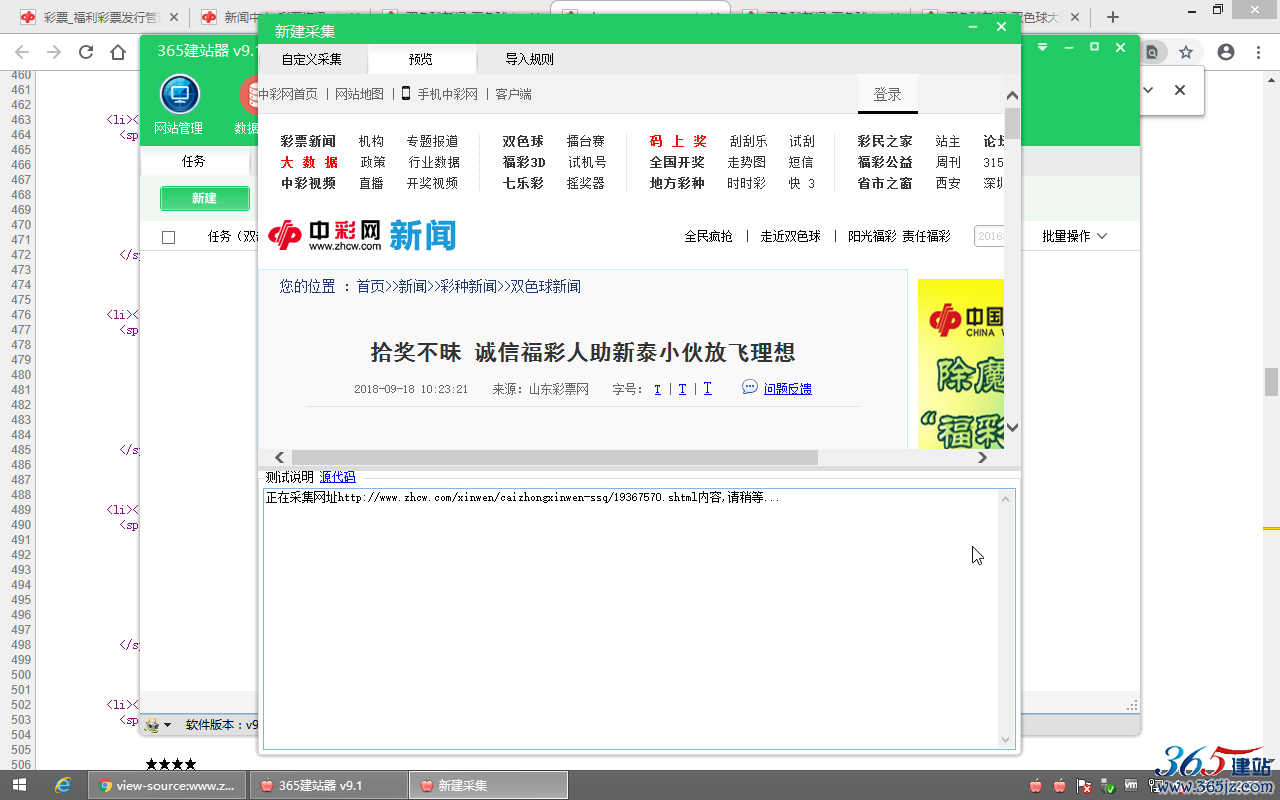
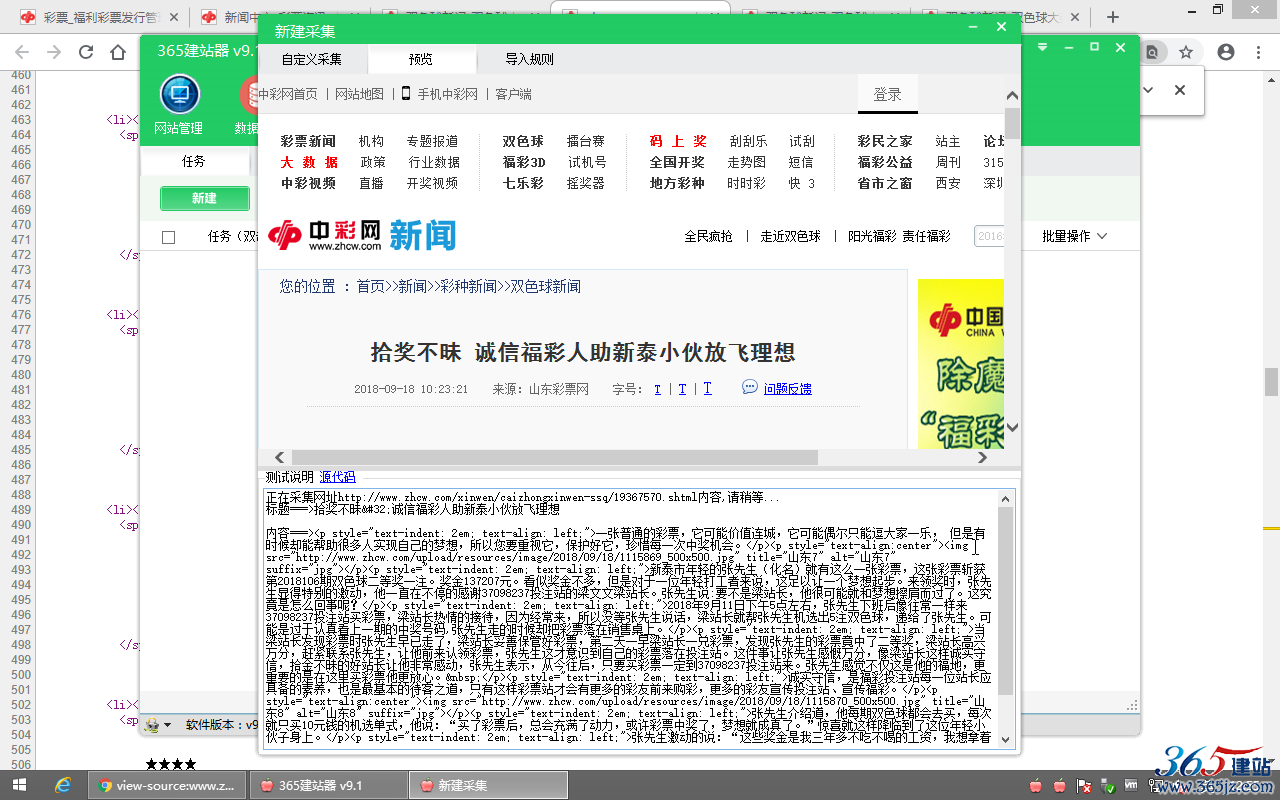
可以看到,公共规则能正确采集到标题与内容,点击下面的“保存”。
如果“公共规则”无法正确采集标题或内容,则可以自定义规则。
7、查看内容页源代码,自定义标题与内容规则:
打开一个内容页源代码,查找标题内容,确定标题前后的字符串:
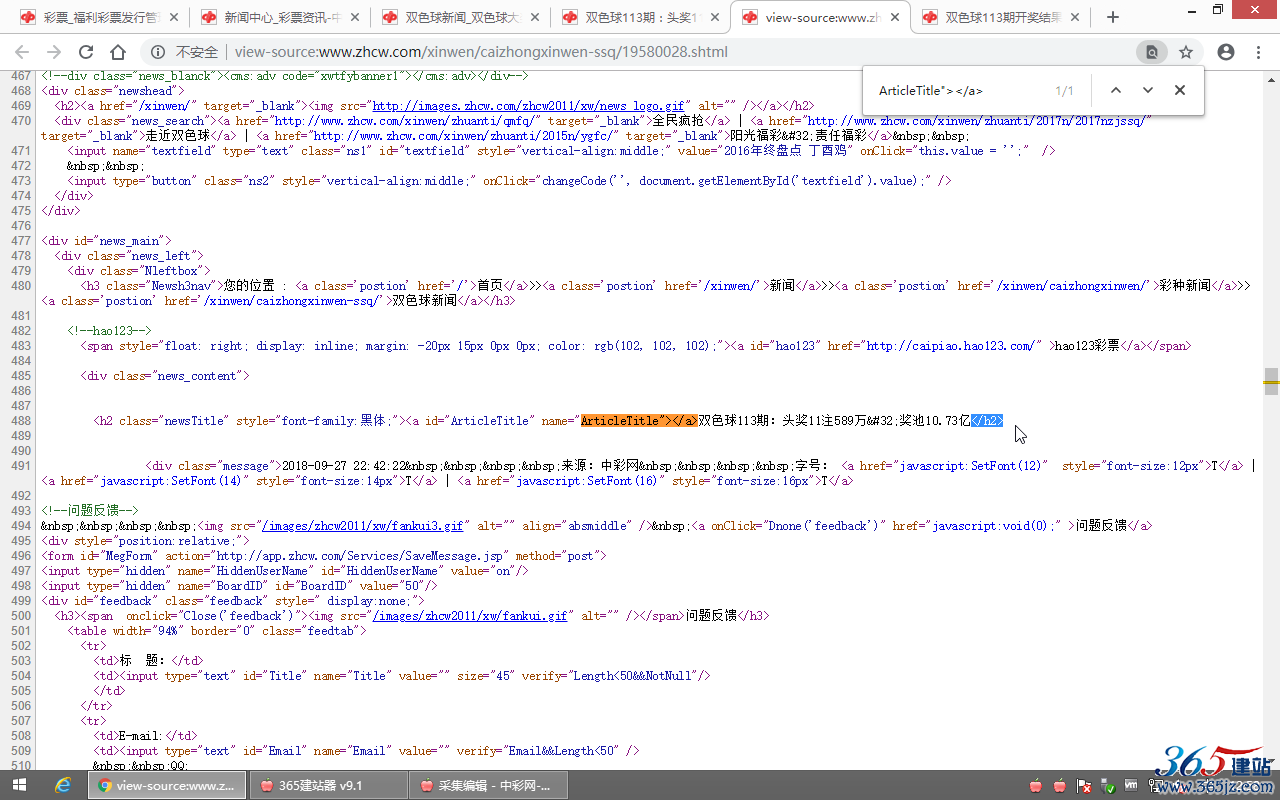
<a id="ArticleTitle" name="ArticleTitle"></a>双色球113期:头奖11注589万 奖池10.73亿</h2>
或者截取短一点:
ArticleTitle"></a>双色球113期:头奖11注589万 奖池10.73亿</h2>
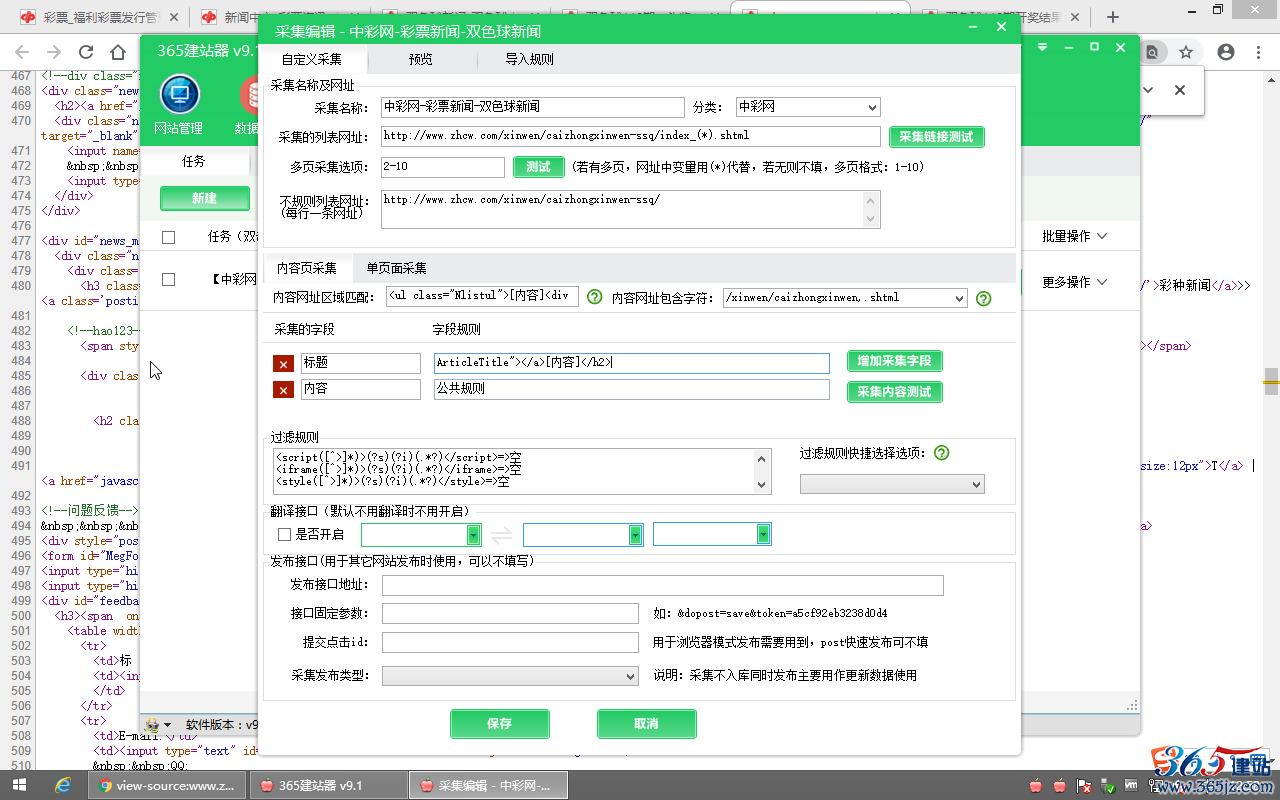
“标题字段规则”,(格式:开头字符串[内容]结尾字符串)
填写:ArticleTitle"></a>[内容]</h2>
再在源代码中查找内容开通和结尾的部分内容,确定内容的前后字符串:
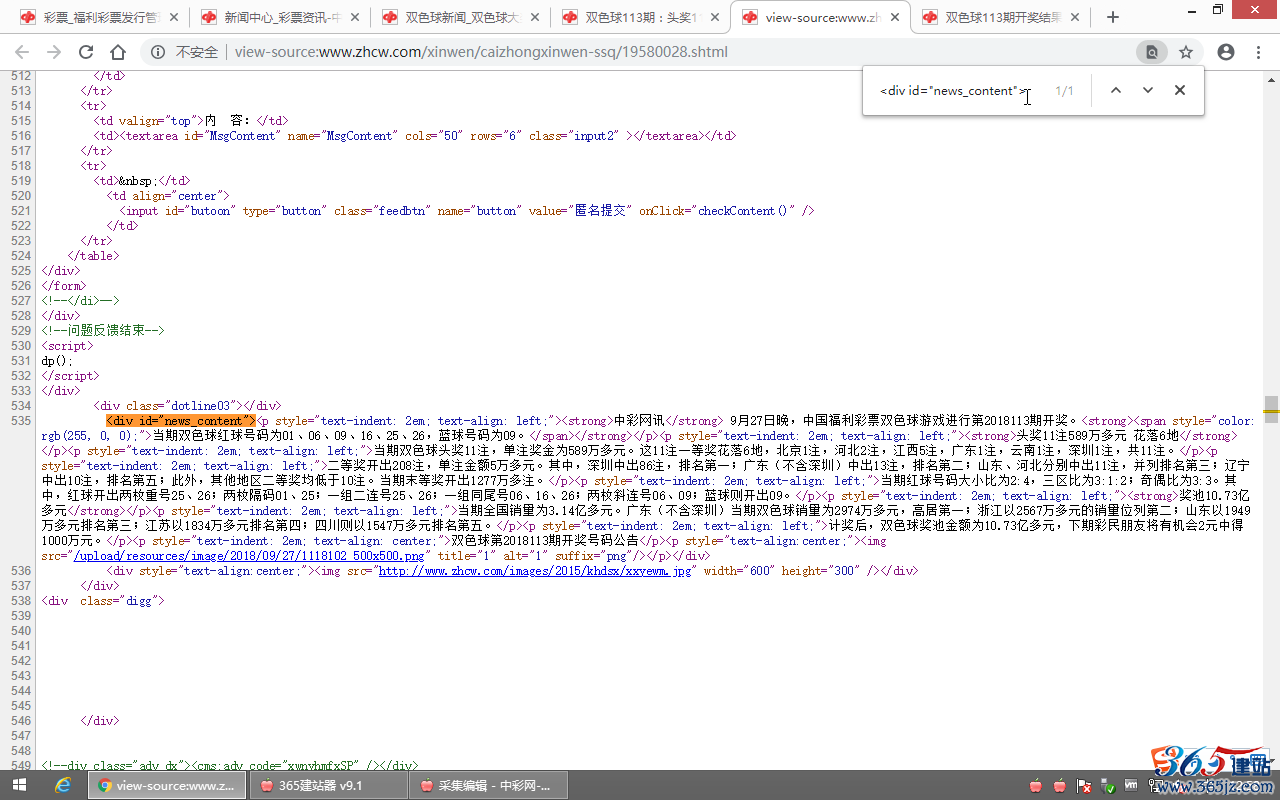
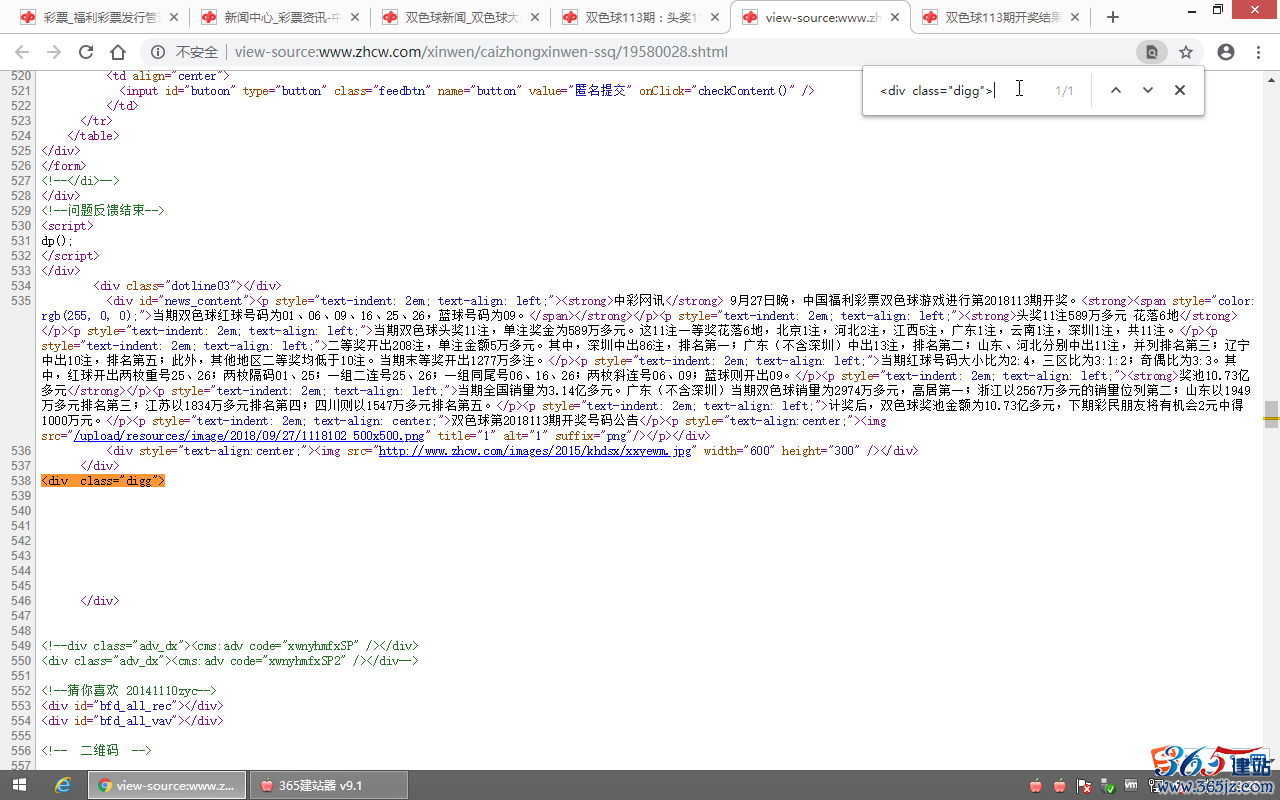
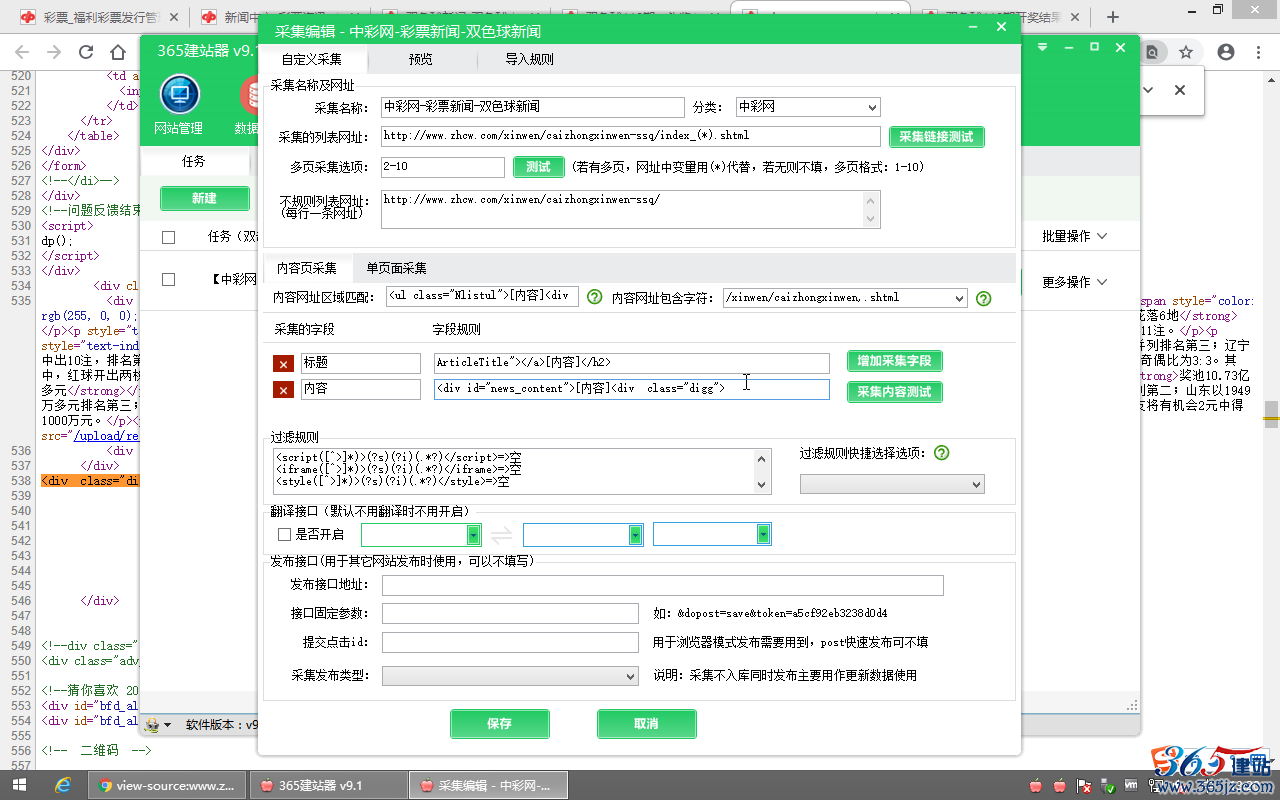
“内容字段规则”,(格式:开头字符串[内容]结尾字符串)
填写:<div id="news_content">[内容]<div class="digg">
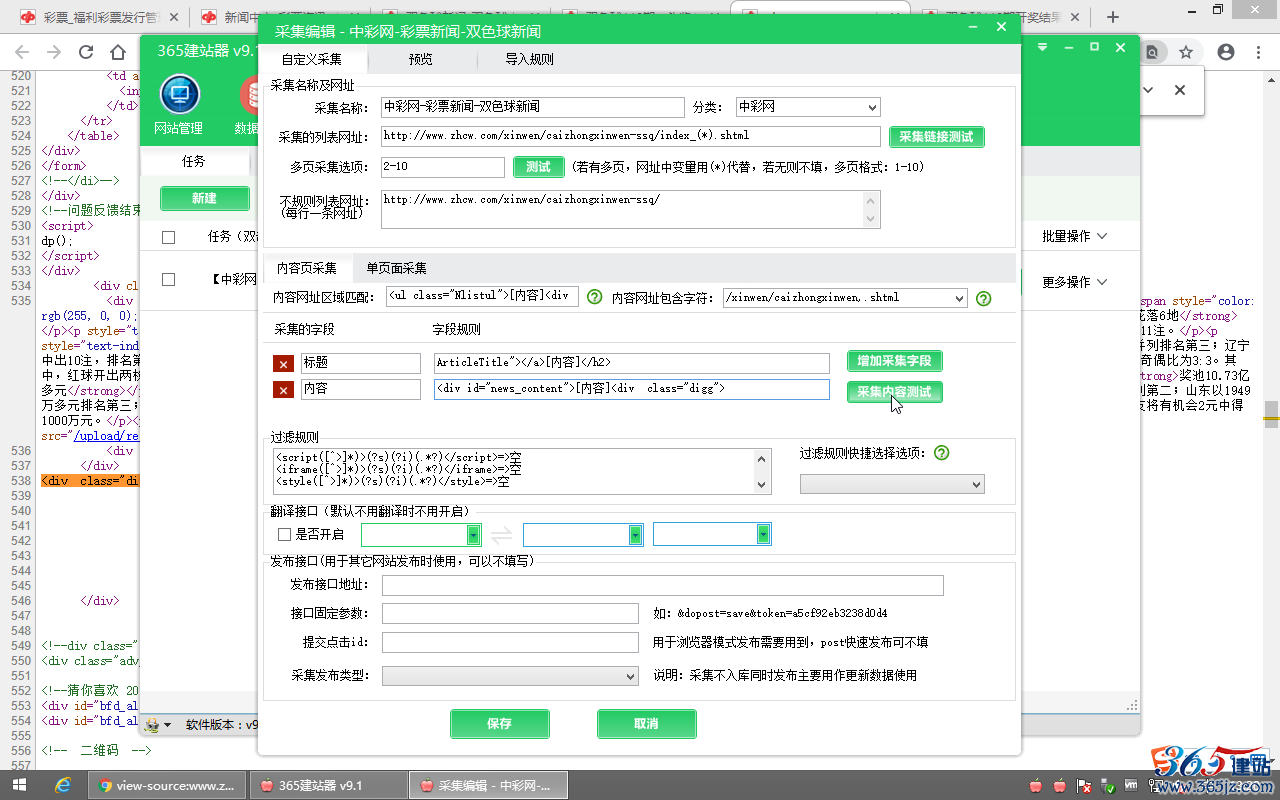
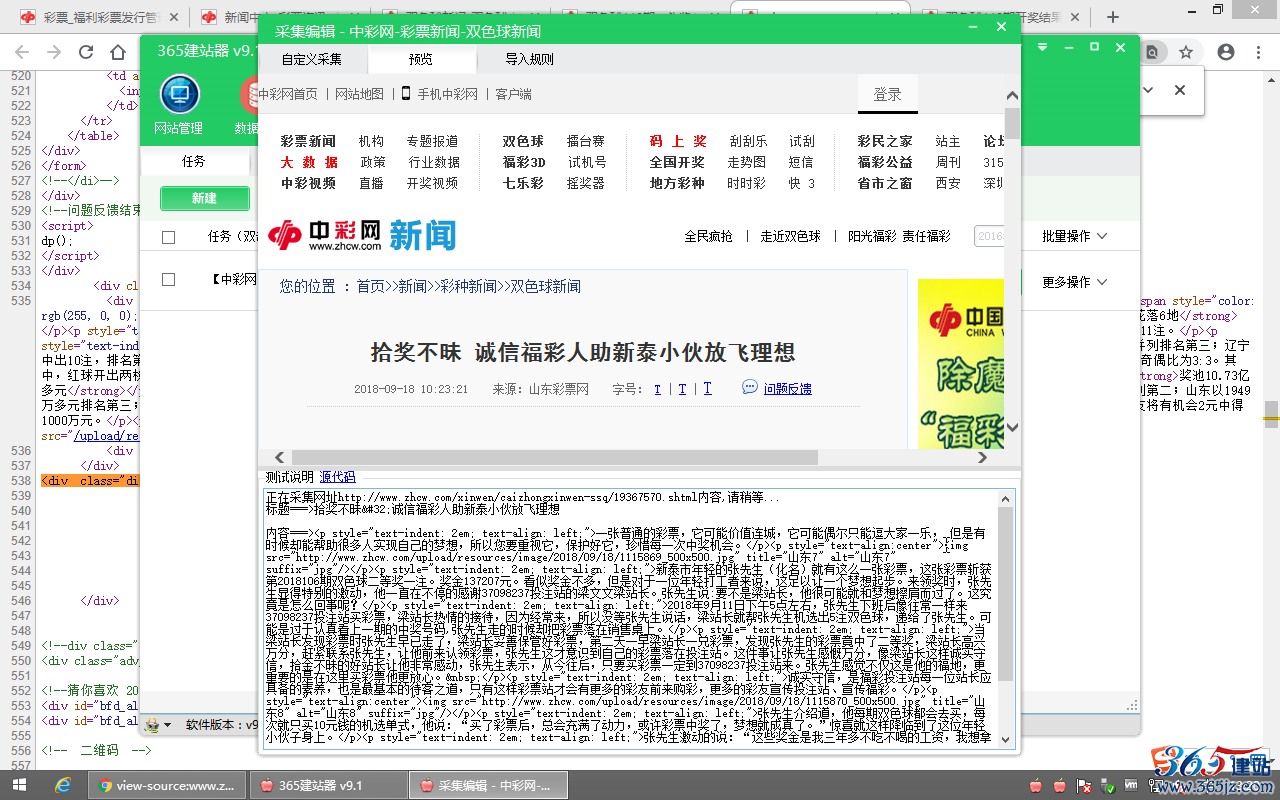
然后点击“采集内容测试”,查看到采集到的标题与内容预览,确认无误:
如果内容中含有不需要的内容,可以使用过滤规则过滤掉,过滤符号为 =>
过滤“中彩网”三个字为空,即删除,过滤规则:
中彩网=>空
替换“中彩网”三个字为“彩票网”,过滤规则:
中彩网=>彩票网
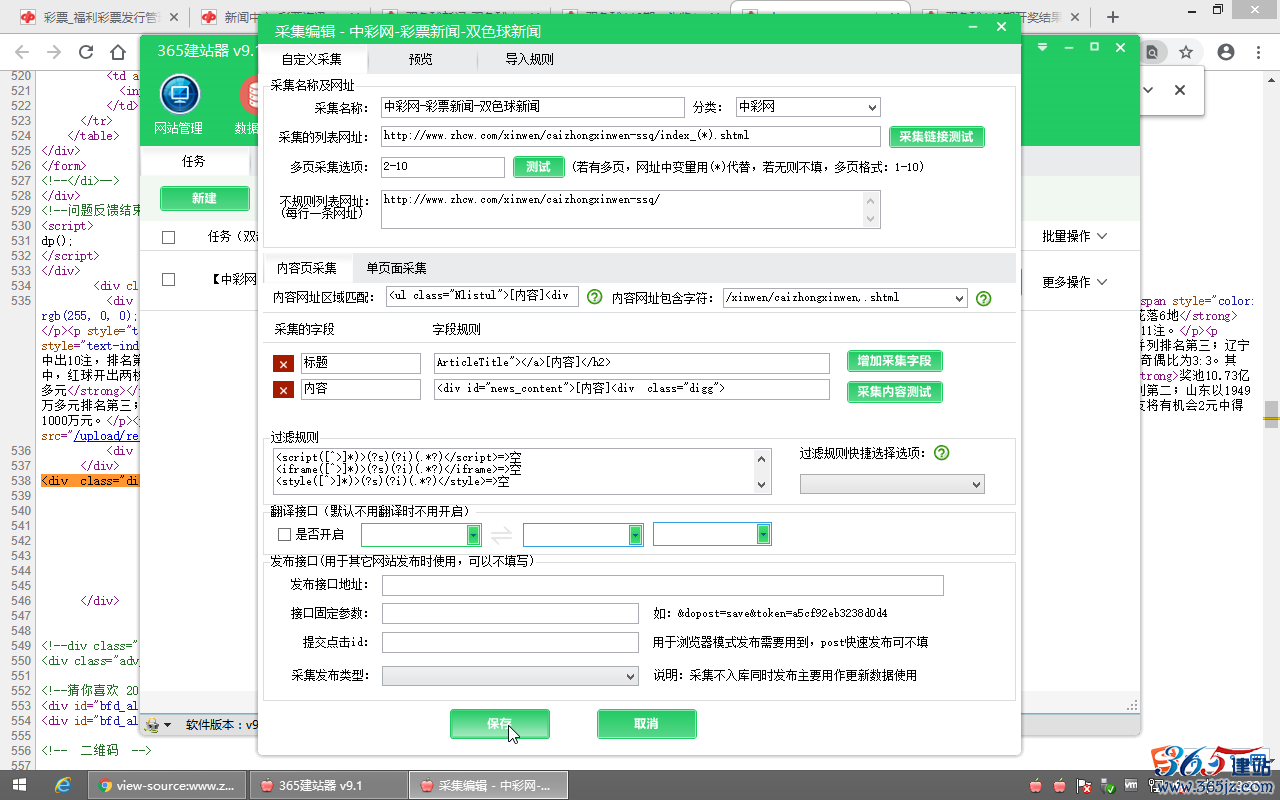
然后点击“保存”填写好的采集规则。
8、开始采集数据,查看采集结果:
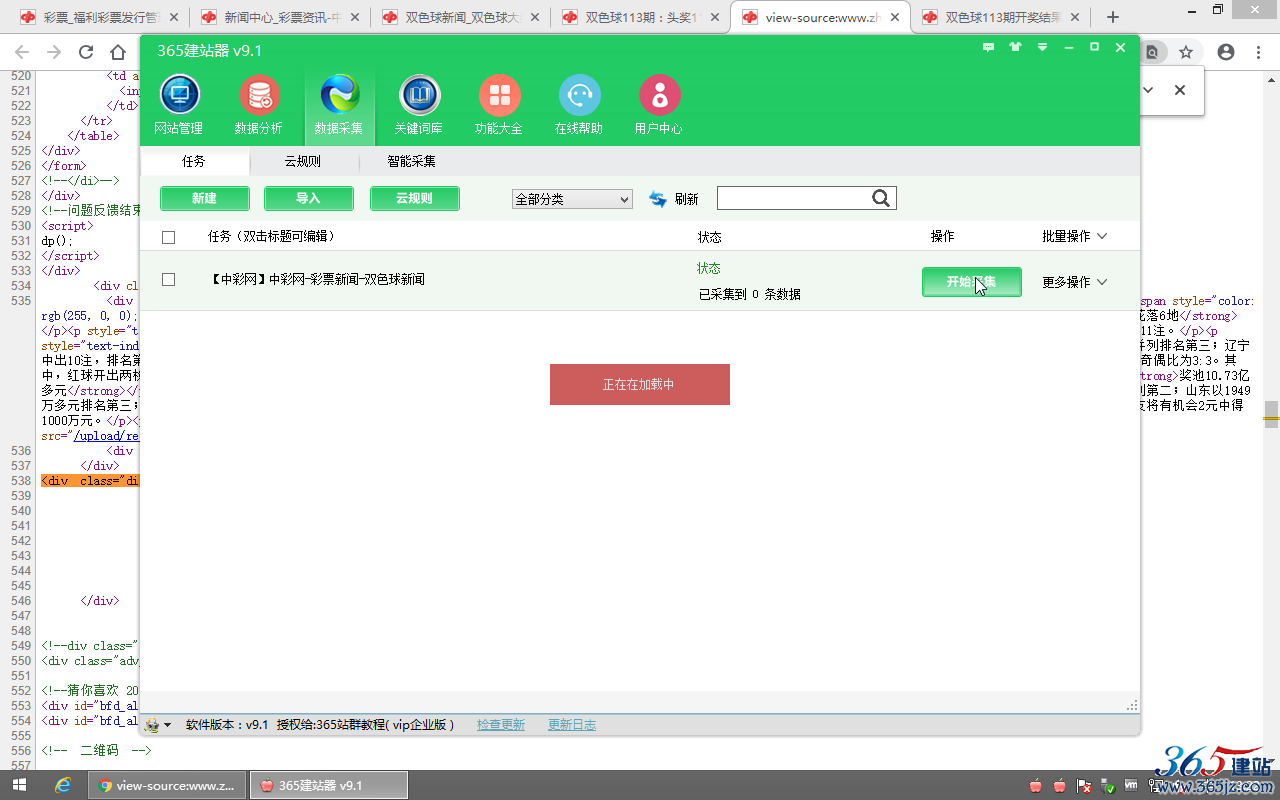
点击“开始采集”。
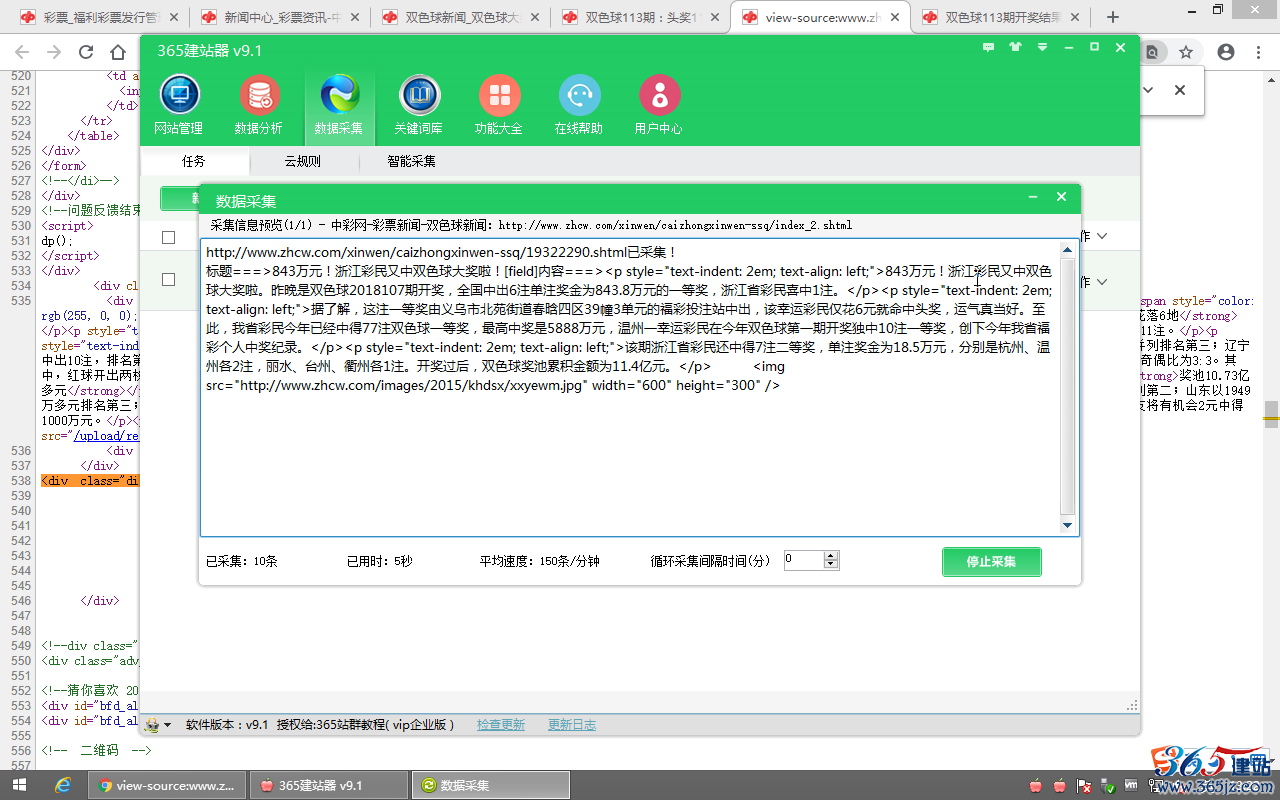
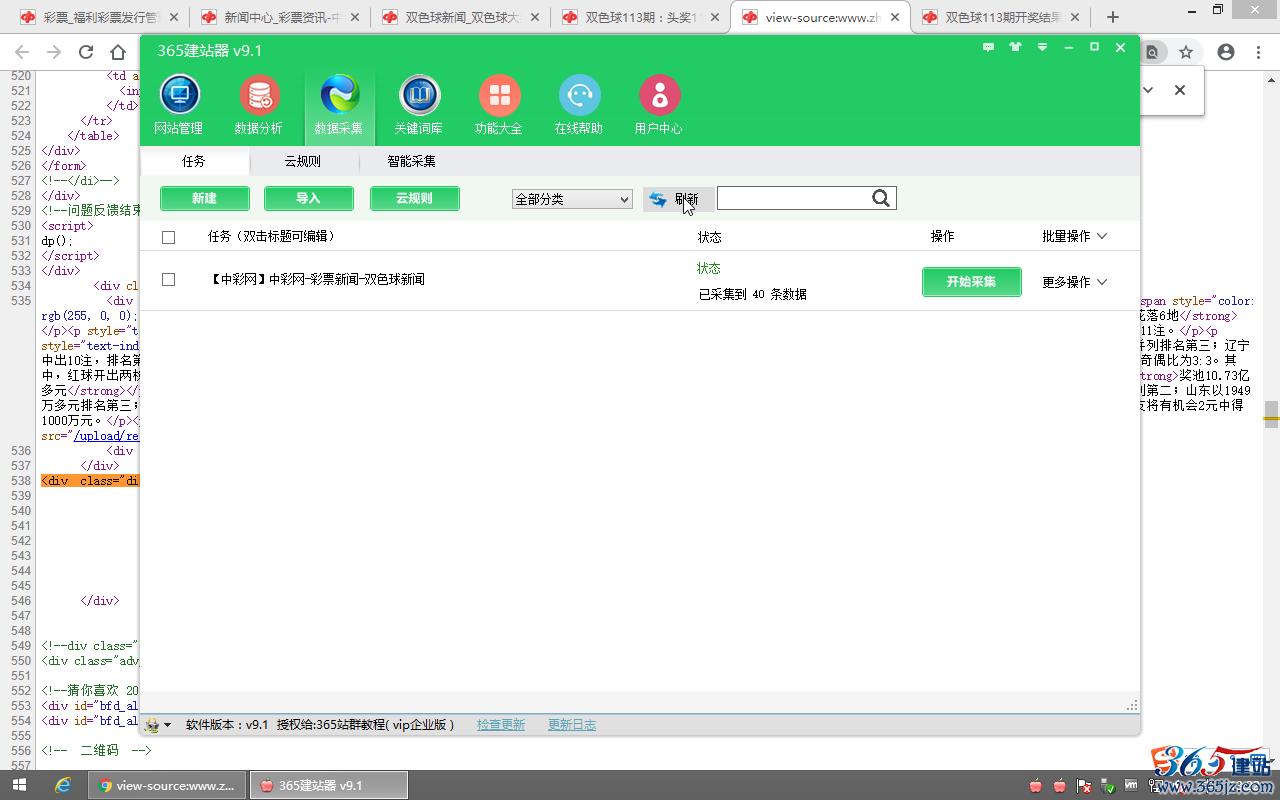
采集停止或者采集完成后,点刷“刷新”查看采集条数。
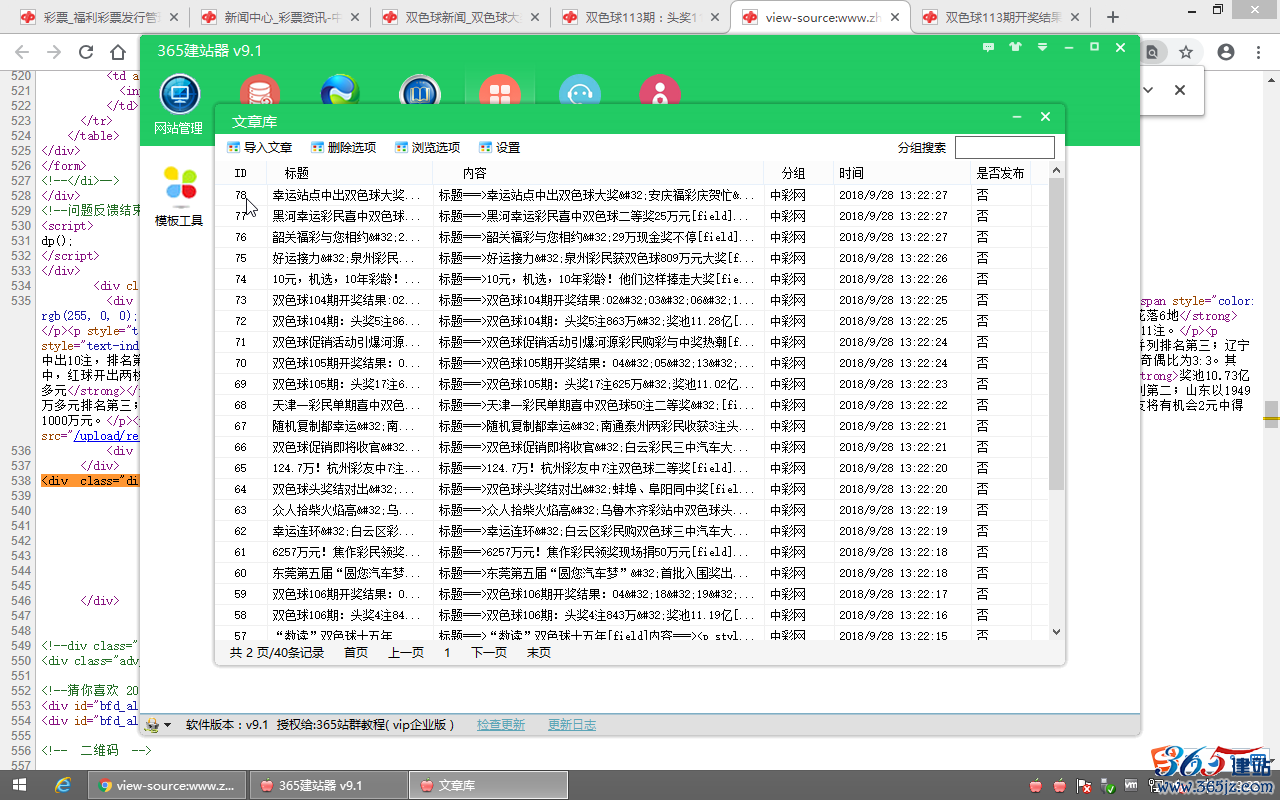
进入“功能大全”,点击“文章库”查看采集的文章结果。
9、特别说明:
推荐使用Google Chrome浏览器,审查元素、查看源代码,方便分析查找规则。
数据采集支持正则表达式,懂正则表达式的用户可以使用正则表达式规则,更方便。
对于规则格式:开头字符串[内容]结尾字符串:
开头字符串:必须是全部源代码中的唯一值,可以Ctrl+F查询,查询结果为1 即可,用于确定采集数据的起点。
结尾字符串:必须是从开头字符串开始算起,在需要采集的内容中间未出现过的值,用于确定采集数据的终点。
10、本教程采集规则汇总:
中彩网-彩票新闻-双色球新闻:
| 采集名称: | 中彩网-彩票新闻-双色球新闻 |
| 分类: | 中彩网 |
| 采集的列表网址: | http://www.zhcw.com/xinwen/caizhongxinwen-ssq/index_(*).shtml |
| 多页采集选项: | 2-10 |
| 不规则列表网址: | http://www.zhcw.com/xinwen/caizhongxinwen-ssq/ |
| 内容网址区域匹配: | <ul class="Nlistul">[内容]<div class="pagebar"> |
| 内容网址包含字符: | /xinwen/caizhongxinwen,.shtml |
| 标题字段规则: | ArticleTitle"></a>[内容]</h2> |
| 内容字段规则: | <div id="news_content">[内容]<div class="digg"> |
中彩网-彩票新闻-双色球中奖报道:
| 采集名称: | 中彩网-彩票新闻-双色球中奖报道 |
| 分类: | 中彩网 |
| 采集的列表网址: | http://www.zhcw.com/xinwen/caimingushi/ssq/index_(*).shtml |
| 多页采集选项: | 2-10 |
| 不规则列表网址: | http://www.zhcw.com/xinwen/caimingushi/ssq/ |
| 内容网址区域匹配: | <ul class="Nlistul">[内容]<div class="pagebar"> |
| 内容网址包含字符: | /xinwen/caimingushi,.shtml |
| 标题字段规则: | ArticleTitle"></a>[内容]</h2> |
| 内容字典规则: | <div id="news_content">[内容]<div class="digg"> |
页:
[1]